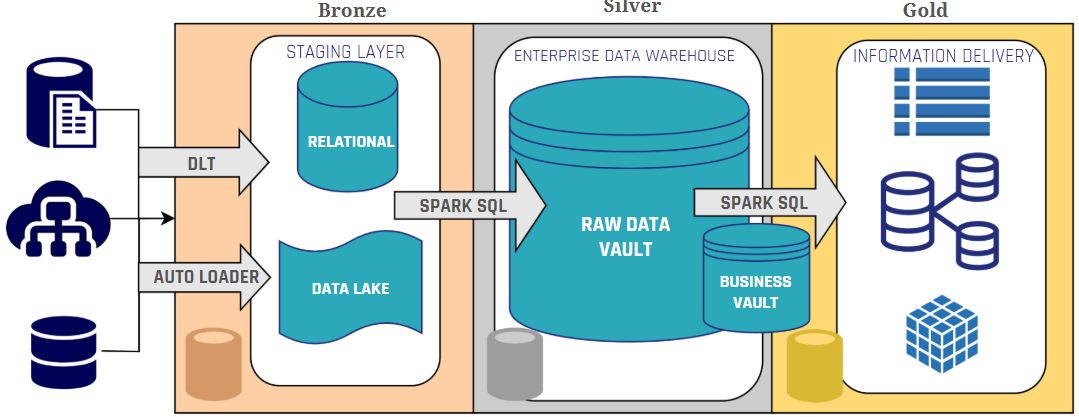
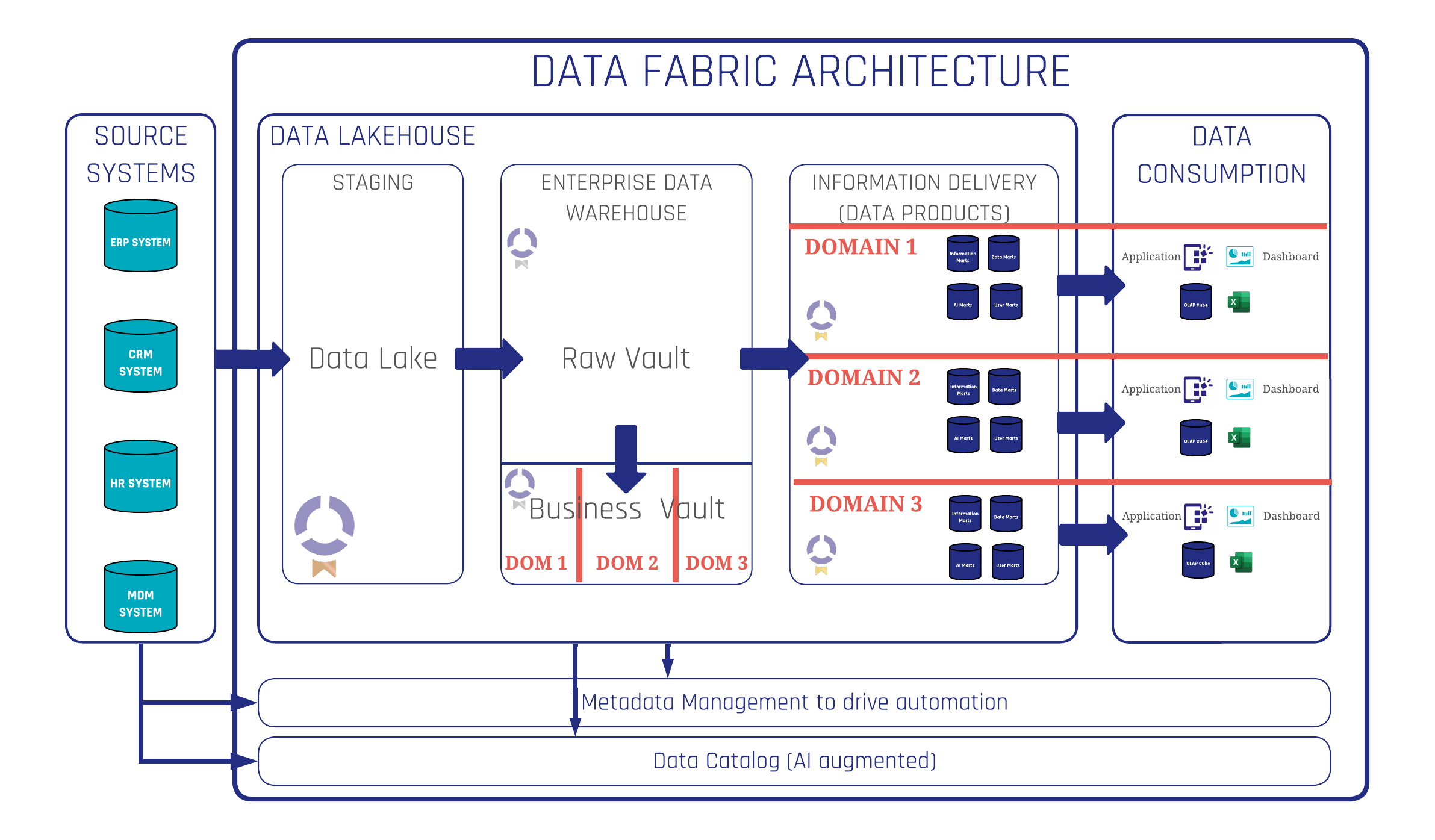
Introduction: The Critical Role of Data Ownership
In today’s rapidly evolving business landscape, managing data effectively is paramount. With increasing regulatory pressures, digital transformation, and a growing reliance on data-driven decision making, clear and defined data ownership becomes a strategic imperative. Without it, organizations risk ambiguity, poor data quality, and non-compliance. This article explores why data ownership is essential for accountability, consistency, and the overall trustworthiness of your data, while providing a clear roadmap to implement effective data stewardship.
The concept is simple: without clearly identifying who is responsible for your data, you invite confusion, inefficiency, and even regulatory penalties. Conversely, establishing clear ownership transforms data from a potential liability into a powerful asset. Whether you are looking to meet the stringent requirements of regulations like GDPR and the EU AI Act, or simply wishing to improve internal communication and decision-making processes, ownership is the key.
Why Data Ownership is Fundamental Today
Let’s delve into the essentials of why data ownership matters. At its core, data ownership is about establishing accountability within an organization. When each segment of data has a designated owner, every piece of information is managed with a specific focus on maintaining quality, compliance, and consistency. This clarity helps in:
- Ensuring Compliance: With defined responsibilities, it’s easier to meet regulatory requirements such as GDPR, detailed ESG reporting, and the complexities of the EU AI Act. Regulatory bodies demand clear traceability of data – knowing who is accountable for it can prevent fines and reputational risk.
- Enabling Data Quality: When someone is responsible for a data domain, they are motivated to maintain its accuracy, timeliness, and overall quality. This creates a trustworthy data environment which is critical for advanced analytics and informed decision-making.
- Aligning Communication: Clear ownership minimizes internal conflicts and misunderstandings between departments. It reduces debates about data definitions and usage, leading to more harmonious and efficient operations.
- Driving Better Decisions: Ultimately, when data is reliable and well-governed, it forms the foundation for strategic planning, innovative analytics, and effective AI implementations.
In essence, effective data ownership isn’t just a technical or operational necessity—it’s a strategic tool that can drive significant business value.
When Data Lacks Ownership: The High Stakes of Unclear Accountability
The oft-quoted phrase “data is the new oil” highlights the immense value of data, yet without clear ownership, its potential can quickly be undermined. Without accountability, several risks emerge:
- Fuzzy Accountability: When it is unclear who is responsible for data, errors and delays multiply. Issues such as inaccurate reports or unresolved data discrepancies can lead to operational inefficiencies and financial losses.
- Poor Quality Data: Without an owner’s vigilant oversight, data quality suffers. Decisions and strategies built on shaky foundations can lead to misguided initiatives and lost opportunities.
- Regulatory Risks: The absence of a clear data ownership structure can turn regulatory compliance into a nightmare. With GDPR, the EU AI Act, and strict ESG standards, non-compliance is not just costly—it can also damage the trust stakeholders have in the business.
Clear data ownership transforms these risks into opportunities. By appointing dedicated owners, organizations can turn data into a reliable, high-quality asset that fuels better decisions, drives innovation, and facilitates compliance.
Understanding Data Ownership Roles: A Team Effort
Data ownership is not about placing the burden on a single person—it’s a collaborative effort that requires distinct roles. Using an analogy of managing a valuable property can help illustrate this clearly:
Data Owner: The Property Owner
Imagine the data owner as the property owner—usually a business leader. They hold the ultimate accountability for a specific data domain, such as customer data or financial records. Their responsibilities include setting policies, defining quality expectations, and deciding who has access to critical data. They focus on leveraging data for strategic advantages.
Data Steward: The Property Manager
The data steward, akin to a property manager, is a subject matter expert responsible for the day-to-day management of the data. They maintain key definitions (metadata), continuously monitor data quality, and promptly address issues. Their role ensures that the data remains fit for purpose—clean, accurate, and understandable.
Data Custodian: The Maintenance Crew
Finally, the data custodian is like the security and maintenance team responsible for the physical upkeep of a property. In data management, this is typically the IT role that oversees the technical infrastructure. They manage storage, implement robust security controls, control backups, and facilitate access—keeping the data safe and technically accessible.
The key takeaway is that these roles must operate in close collaboration. While each function is distinct, together they create a comprehensive framework that supports secure, reliable, and high-quality data management.
Common Pitfalls in Establishing Data Ownership
Even the most well-intentioned organizations can stumble in implementing data ownership. Understanding common pitfalls is crucial to designing a more practical and effective approach.
- Lack of Clarity: Often, data ownership exists only on paper. When roles are not operationalized in day-to-day activities, everyone ends up assuming that someone else is responsible for data quality and governance.
- “Not My Job” Syndrome: Diffusion of responsibility can lead to a culture where critical data falls through the cracks because every team member assumes someone else owns it.
- Missing Authority: Assigning someone as a data owner without providing the real power, time, or resources to enforce decisions hinders effective data governance.
- Defaulting to IT: A common error is to assume that IT should automatically be the data owner. However, the true understanding of data often lies within the business side where its meaning and implications are most evident.
- Overcomplicating the Process: Trying to implement perfect data ownership across every aspect of an organization at once can lead to analysis paralysis. It’s essential to start small and build progressively.
- Misplaced Faith in Tools: Technology alone, such as data catalogues or governance platforms, cannot solve ownership problems. Without defining the people and processes involved, these tools will only add layers of complexity.
Recognizing and avoiding these pitfalls paves the way for a more pragmatic and sustainable approach to data ownership.
A Pragmatic 5-Step Approach to Effective Data Ownership
Instead of being overwhelmed by the complexities, organizations can follow a pragmatic step-by-step approach to implement data ownership effectively.
- Start Small & Focused: Identify one or two critical data domains where the issues are most significant. Whether it’s customer contact information or key financial data, focusing on a few areas initially can deliver rapid improvements.
- Appoint and Empower REAL Owners: Assign business leaders as the owners, ensuring they have both the authority and mandate to enforce decisions. It is vital to support them with the necessary resources to act decisively.
- Create an Ownership Charter: Draft a simple yet comprehensive charter that documents the roles—Data Owner, Steward, and Custodian—their core responsibilities, and the key processes. This document should define data elements clearly and establish an escalation process.
- Track and Communicate: Implement basic metrics to measure data quality, such as completeness, accuracy, and timeliness. Dashboards and regular reports can provide transparency and keep everyone aligned.
- Build a Shared Understanding: Develop a common data language across the organization. Use a business glossary and data lineage maps to ensure that every stakeholder is on the same page. Formalize handoffs between teams with clear data delivery agreements.
By following these steps, organizations can establish a culture of accountability and quality, turning data ownership into a powerful driver of business success.
What ‘Good’ Data Ownership Looks Like
When data ownership is effectively established, organizations experience significant benefits, including:
- Reduced Risk & Faster Issue Resolution: With a designated owner, issues are identified and resolved promptly, reducing the risk of prolonged disruptions and costly errors.
- Smoother Compliance: Audits and regulatory inspections become less stressful and more straightforward, as clear audit trails and accountability measures are in place.
- Enhanced Decision-Making: Trusted data leads to smarter, data-driven decisions. It enables reliable analytics, robust business intelligence (BI), and even more effective artificial intelligence (AI) strategies.
- Increased Operational Efficiency: Teams spend less time searching for data or fixing errors. Clear ownership reduces friction, ultimately speeding up decision-making processes.
- A Culture of Responsibility: When data is viewed as a shared asset, collaboration increases and data is treated with the care it deserves. This shifts the organizational mindset towards continuous improvement and value creation.
In summary, good data ownership turns what could be a cumbersome obligation into a strategic asset that bolsters every facet of an organization—from compliance and risk management to innovation and operational agility.
Conclusion: Empower Your Organization with Clear Data Ownership
Data ownership is more than an administrative necessity; it is a strategic asset that underpins compliance, quality, and overall business success. By clearly defining who is responsible for data, organizations can ensure that information is managed with precision, accountability, and a strategic focus on value creation.
Remember, the journey starts by identifying key data domains where the pain points are most pronounced. Once you appoint responsible owners and empower them with real authority and clear charter documents, you create an environment where data is nurtured, trusted, and effectively leveraged. This approach not only minimizes risks and regulatory challenges but also sets the stage for innovation and smarter decision-making.
As you move forward, ask yourself: What is the first critical data domain in your organization where clear ownership could unlock real value? The answer to this question may well be the catalyst for transforming your data from a potential liability into your most valued asset.
Embrace the principles of effective data ownership today, and watch as your organization evolves into a more agile, confident, and data-driven powerhouse.