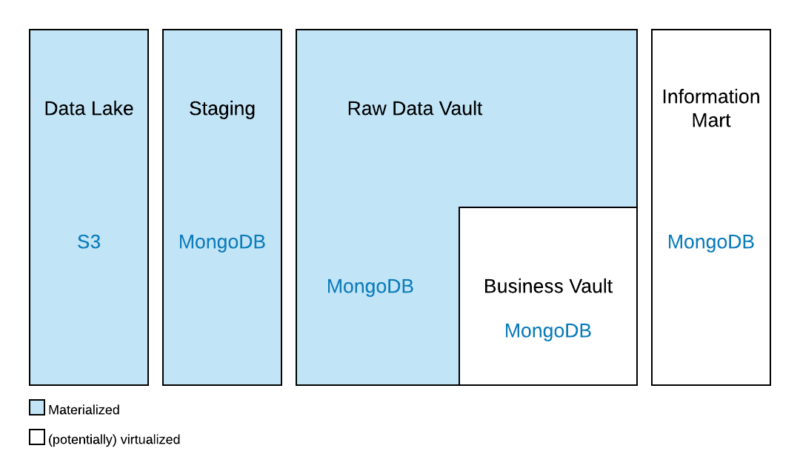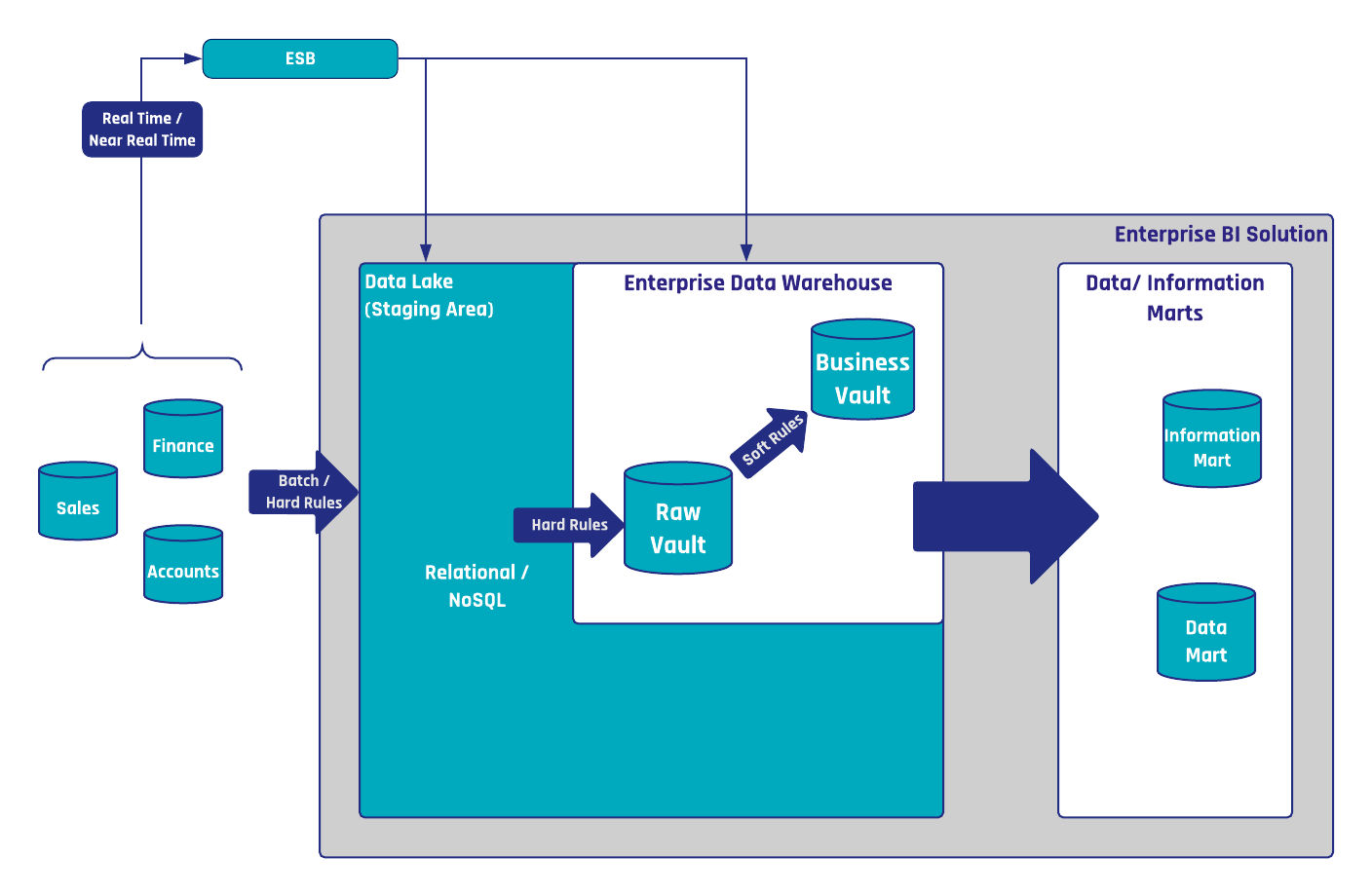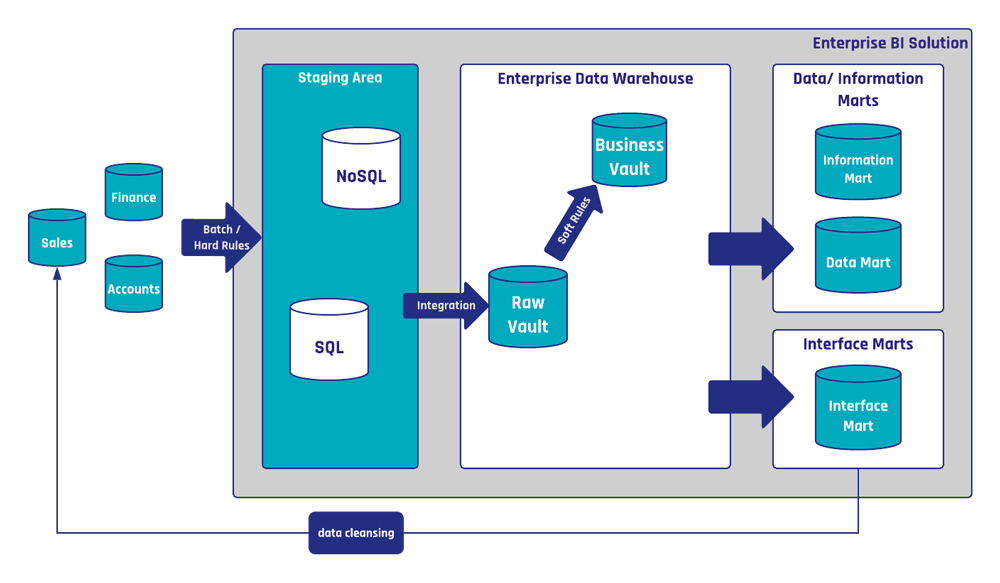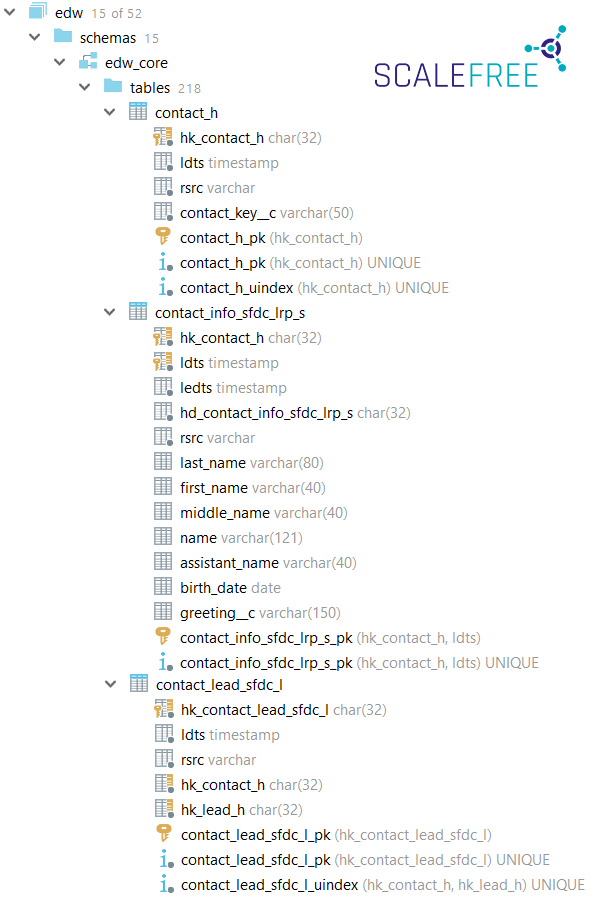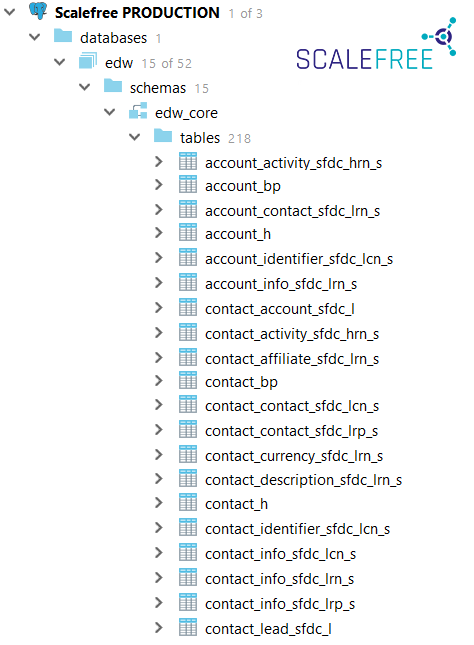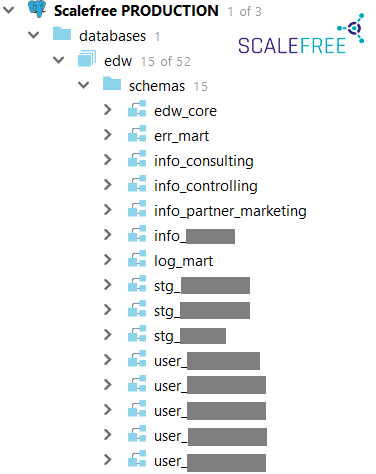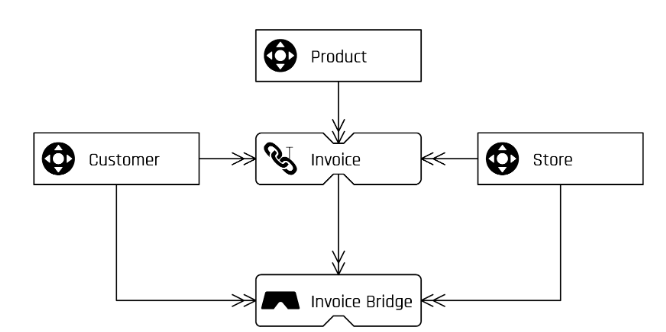
Both systems should be technically integrated, which means if a new customer signs up for a home insurance policy, the customer’s data should be synchronized into the car insurance policy system as well and kept in sync at all times. Thus, when the customer relocates, the new address is updated within both systems.
Though in reality, it often doesn’t go quite as one would expect, as, first of all, both systems are usually not well integrated or simply not integrated at all. Adding to the complexity, in some worst-case scenarios, data is manually copied from one system to the next and updates are not applied to all datasets in a consistent fashion but only to some, leading to inconsistent, contradicting source datasets. The same situation applies often to data sets after mergers and acquisitions are made within an organization.