Watch the Webinar

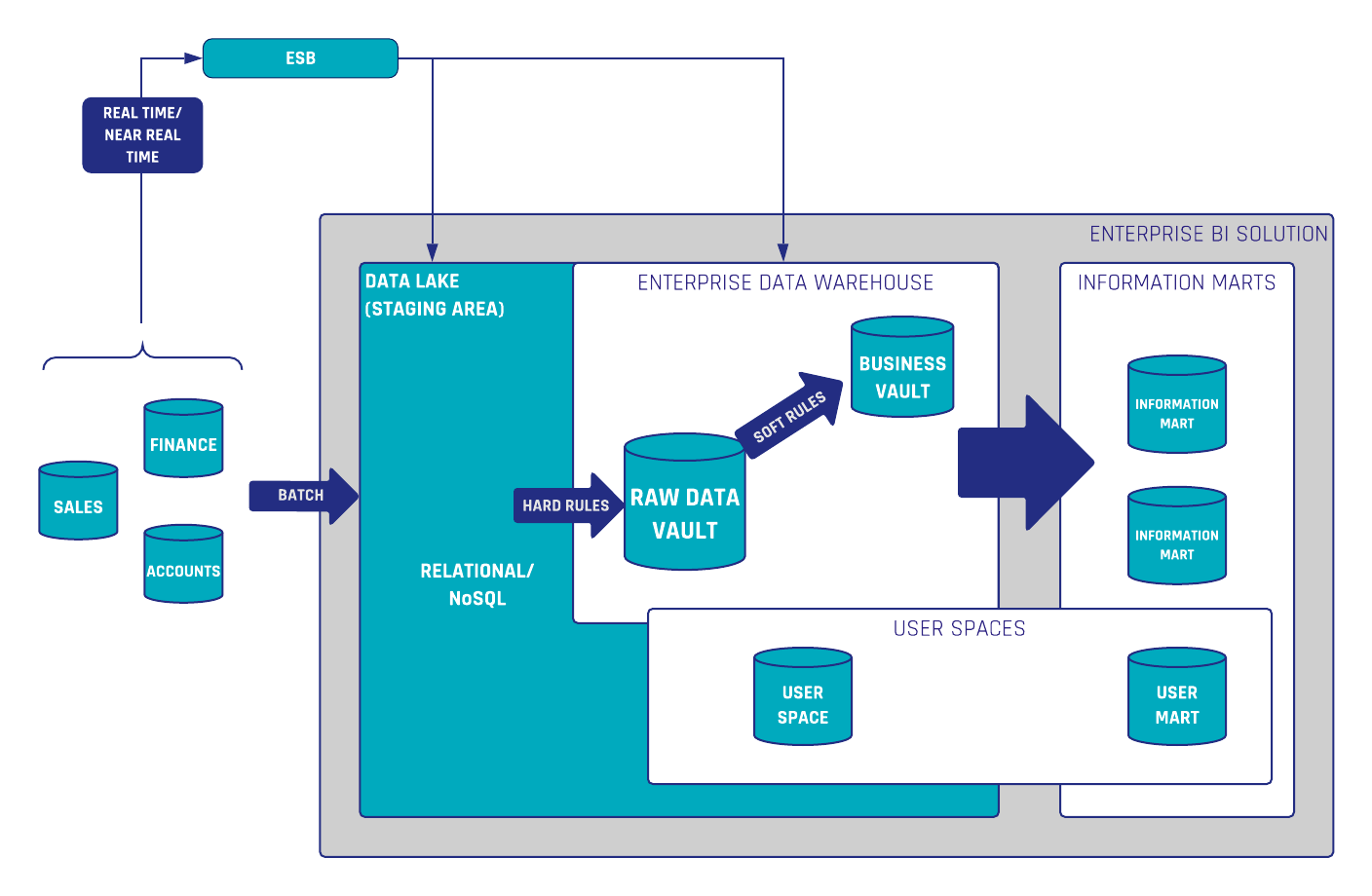
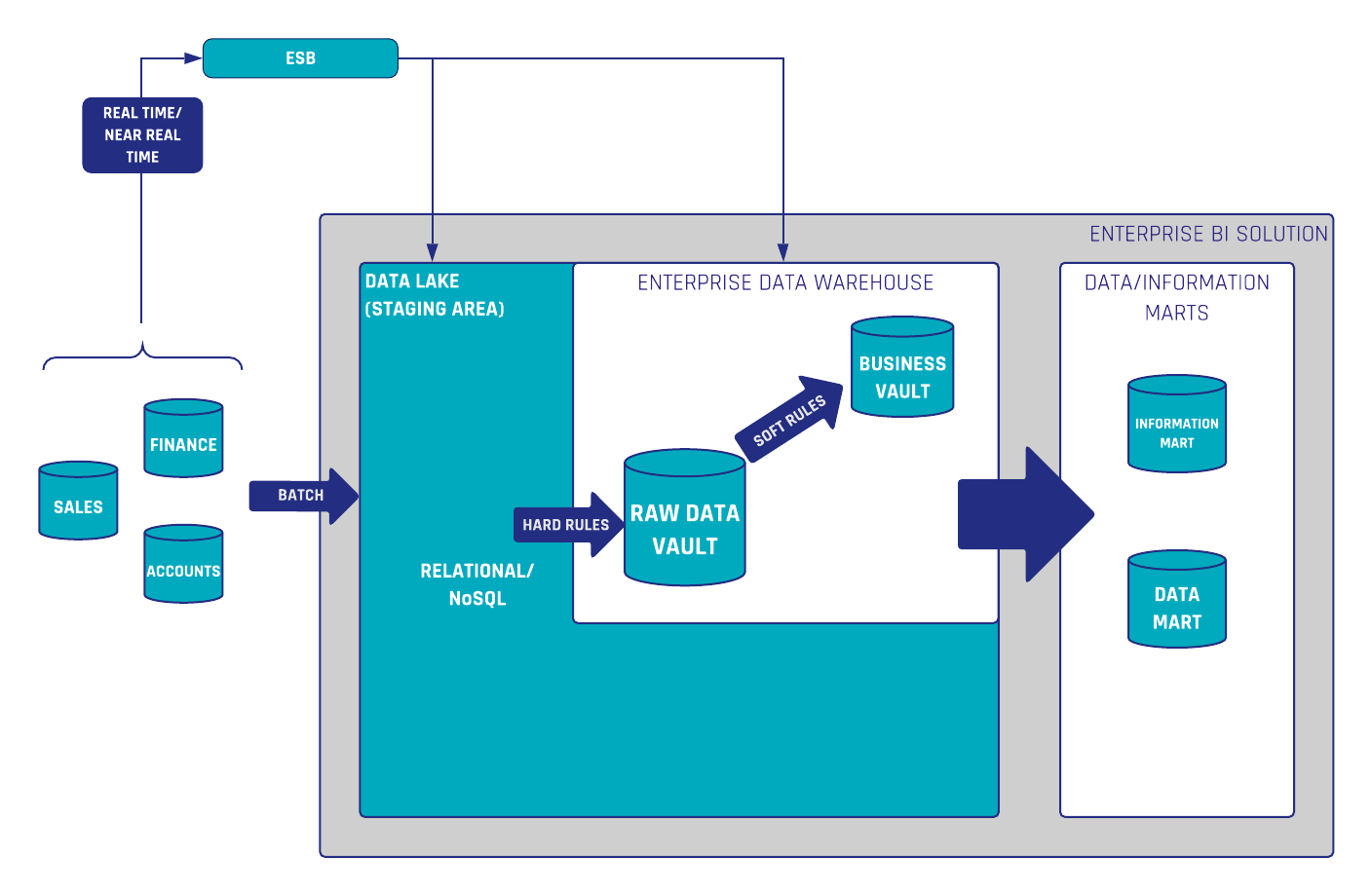
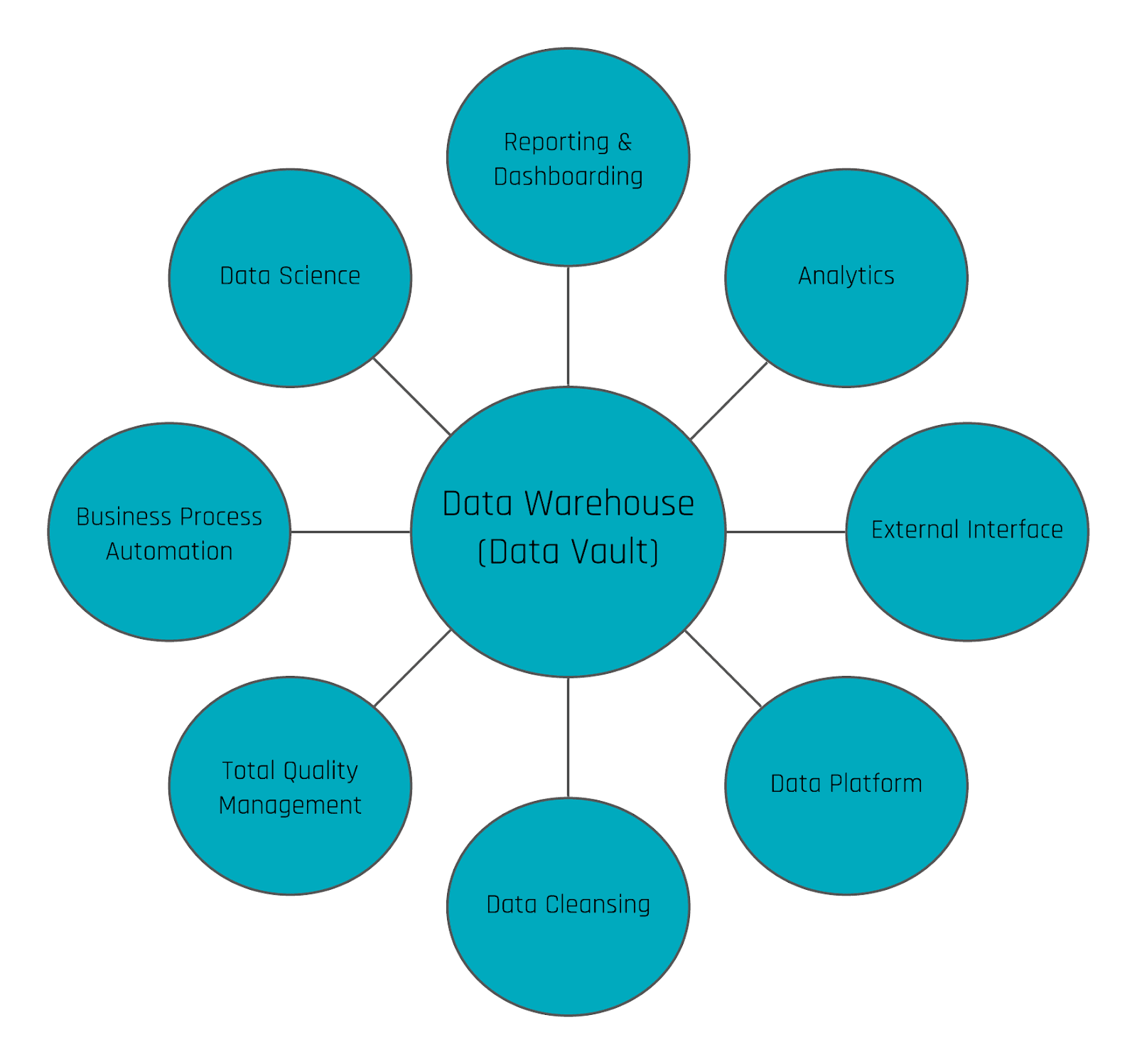
Data Vault and Snowflake in combination are constituting flexible and scalable Enterprise Data Warehouse solutions.
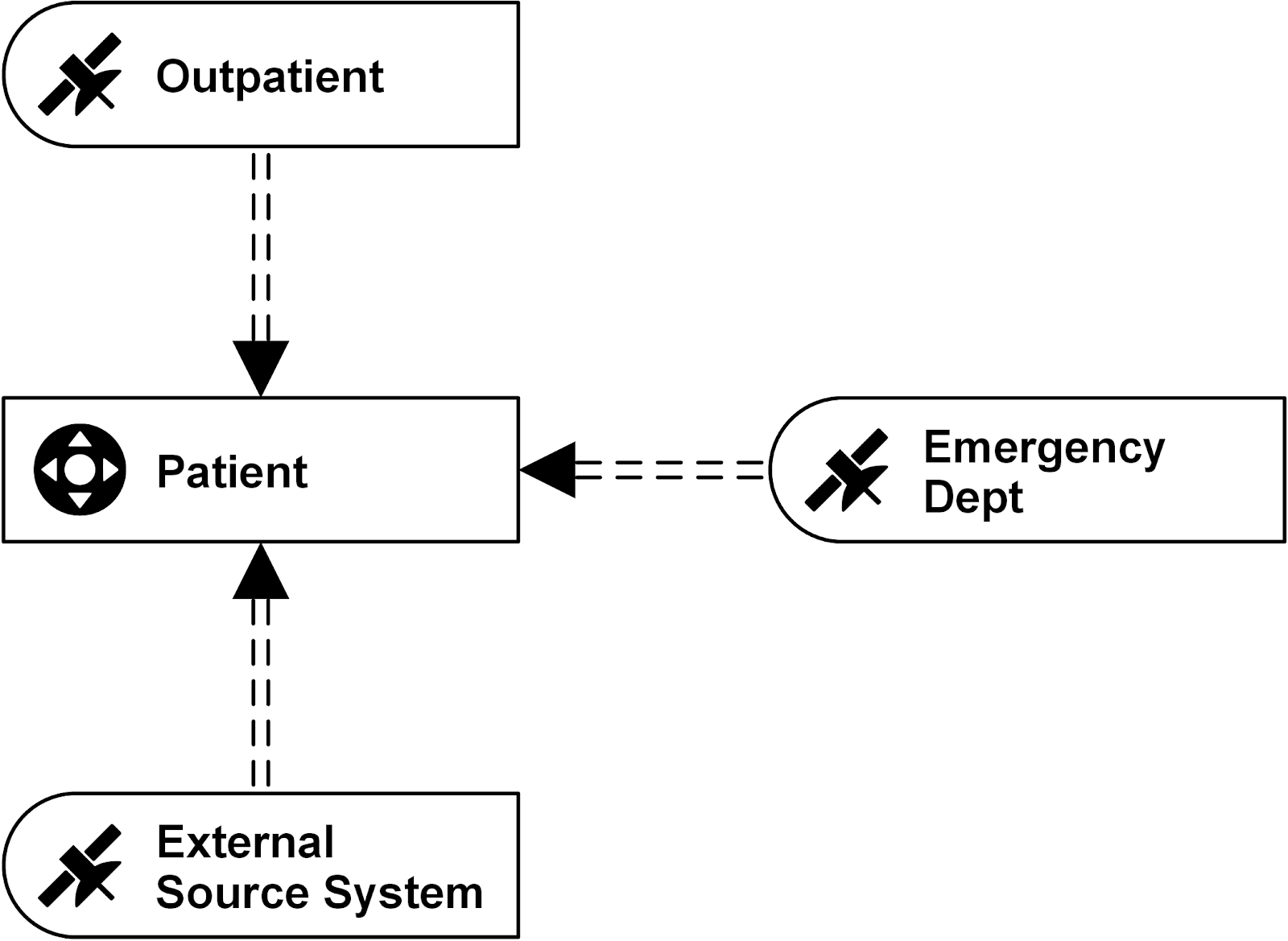
Attendees will get insights about building and loading a GDPR-compliant Data Lake (AWS) and Data Vault model. The loading and querying processes have a great scalability within Snowflake.
The webinar includes a live demo from Snowflake showing Data Ingestion, Variant Data Types, and Data Sharing opportunities.
Watch Webinar Recording
Webinar Agenda
1. Intro
2. Accelerate your Data Vault with Snowflake (Scalefree)
3. Snowflake Demo (Snowflake)