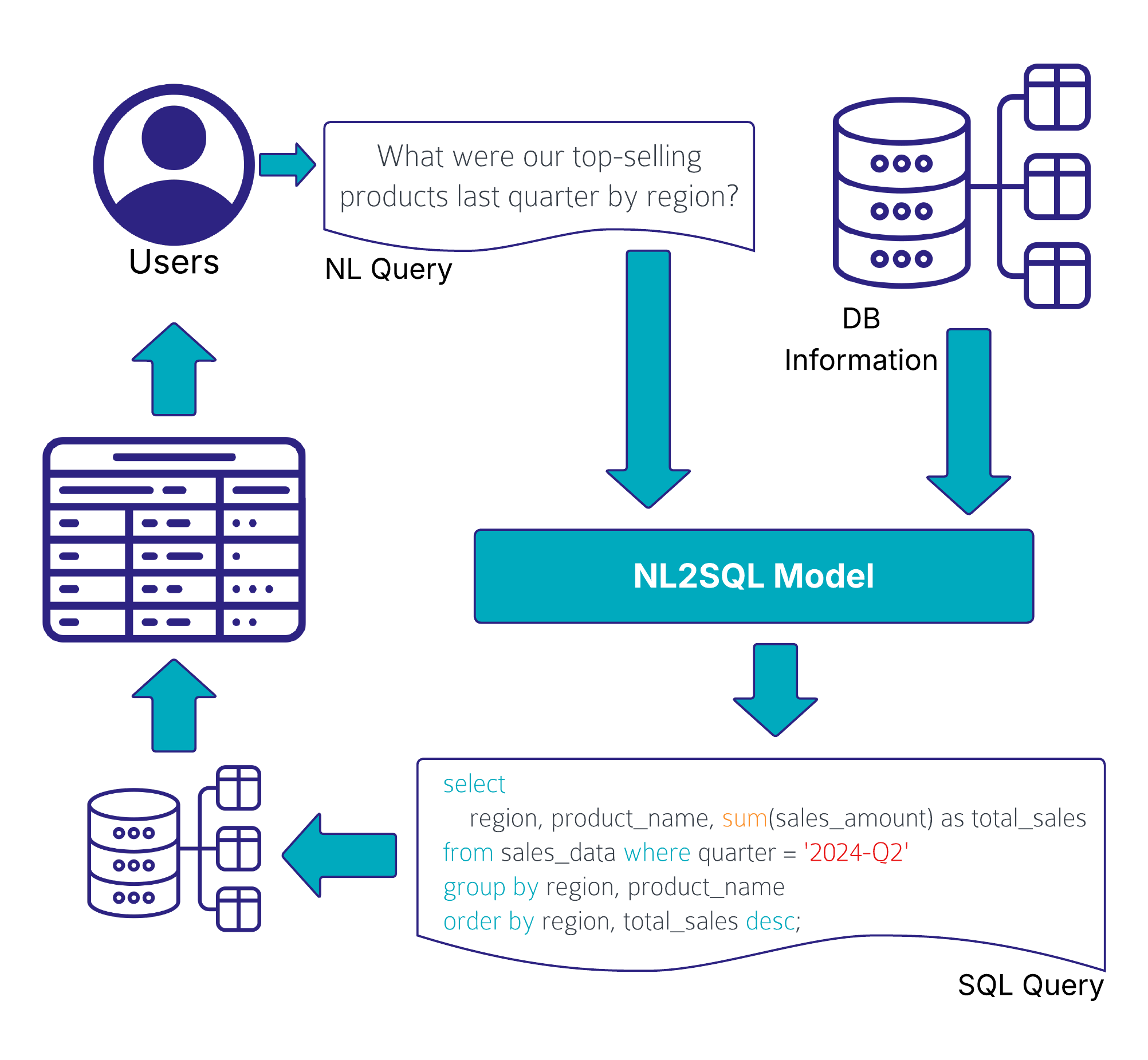
Introduction to BI Solutions
Business intelligence (BI) and AI-driven analytics are no longer niche support functions — they are strategic products that touch product, ops, finance, compliance and customer experience. As BI expands from traditional reporting into real-time analytics, predictive modeling and self-service, the shape of data teams and the way they work are changing fast. This article summarizes the main drivers of that change, the practical impacts on teams and projects, and concrete responses you can apply now to reduce risk and keep delivering value.
In this article:
Why complexity is rising: five key challenges
Modern BI projects are visiting new territory. Below are five core challenges that repeatedly appear across industries and organizations.
1. Broader scope
BI today must do more than historical reporting. Stakeholders expect real-time dashboards, anomaly detection, predictive forecasts and self-service capabilities — often from the same platform. That breadth increases integration points, testing surface and the number of decisions that must be made early in the project.
2. Broader skillset
Delivering modern analytics requires a richer set of roles: data engineers who build pipelines, data modelers who craft semantic layers, data scientists who build predictive models, UX designers who make outputs usable, and governance specialists who protect privacy and ensure compliance. It’s rare for one person to cover all of these competently.
3. Increased coordination
More roles equals more handoffs. Each handoff is a potential point of misunderstanding — different assumptions, different definitions, different delivery cadences. Without deliberate coordination, projects fragment into disconnected workstreams.
4. Technical revolution
BI and cloud platforms evolve rapidly. New services, improved runtimes and updated best practices arrive often. Teams must continuously upskill and decide which innovations to adopt, and when. Certification cycles and vendor roadmaps move fast — staying current costs time and creates churn.
5. Balancing agility and governance
Stakeholders want rapid delivery and iterative improvement. At the same time, many industries require strict data handling, privacy controls and auditability. Finding an operating model that supports quick experiments while preserving accuracy and regulatory compliance is a central tension for modern BI teams.
Typical impacts on organizations
Those drivers produce predictable impacts on teams and delivery models. If unaddressed, they create bottlenecks and risk.
- Role specialization: Teams move toward niche expertise rather than single-person full-stack delivery. That boosts depth but can reduce flexibility.
- Stronger collaboration needs: Alignment across roles becomes essential to avoid silos and inconsistent decisions.
- Higher dependency chains: A delay in one role (e.g., data engineering) can block downstream teams (reporting, model validation).
- Greater governance needs: Shared definitions, standards and processes become mandatory to ensure trust, auditability and repeatability.
Practical responses: four core actions
Complexity is manageable when teams adopt clear practices focused on responsibility, agility, shared knowledge and training. Below are four practical responses that reduce friction and increase predictability.
1. Define clear responsibilities
Clarify who owns each stage of the data lifecycle: extraction, transformation, modeling, publication and maintenance. Use simple role definitions and RACI (Responsible, Accountable, Consulted, Informed) charts for every project. When people know who to ask and who will act, coordination overhead drops and turnaround time improves.
2. Use the best agile approach for your context
Agile isn’t one-size-fits-all. For a fast-moving SaaS product team, continuous delivery and short sprints might be ideal. For a bank with heavy regulation, a scaled framework with gated releases and stronger QA may be necessary. Choose the agile flavor (Scrum, Kanban, SAFe or a hybrid) that balances speed with the required controls — and make those rules explicit to stakeholders.
3. Implement shared documentation and data cataloging
Documentation isn’t optional — it is the connective tissue of modern BI. Practical, searchable documentation and a data catalog with lineage, owners and semantic definitions reduce onboarding time and prevent duplicated work. Track data lineage so teams can answer “where did this value come from?” quickly, and attach clear owners to key datasets and metrics.
4. Invest in cross-training
Cross-training creates T-shaped team members: specialists with enough adjacent knowledge to collaborate effectively. Data engineers who understand reporting constraints, and BI analysts who understand pipeline limitations, can resolve many issues without escalating. Cross-training also builds empathy — teams that understand each other’s constraints make better trade-offs.
Operational checklist you can use today
Use this short checklist to reduce immediate friction on a new or existing BI project.
- Run a one-hour roles workshop: Map responsibilities and publish a RACI for the first three deliverables.
- Choose an agile cadence: Decide sprint length, release gates and who signs off on production models or dashboards.
- Set up a minimal data catalog: Start with your top 10 datasets and add owners, a short description and lineage.
- Schedule cross-training sessions: One hour per week where a team member shares how they work and what they need from others.
- Document privacy and compliance rules: Keep them accessible and tie them to datasets and pipelines.
Common pitfalls and how to avoid them
Even with good intentions, teams stumble. Here are three pitfalls to watch for and short fixes.
Pitfall: Documentation as a chore
Fix: Make documentation part of the workflow. Use templates, require a one-line summary when a dataset changes, and keep a lightweight catalog rather than one massive, stale repository.
Pitfall: Over-specialization that creates handoff bottlenecks
Fix: Rotate or pair people for critical tasks. Pair a report developer with the data engineer for the first run of a new dashboard so knowledge spreads and the dependency weakens.
Pitfall: Chasing every new tool
Fix: Adopt a “value before novelty” rule. Evaluate new technologies against clear criteria: maintainability, onboarding cost, security and measurable improvement to outcomes.
Leadership and culture: the invisible infrastructure
Technical practices are important, but culture and leadership set the pace. Leaders must invest time in alignment, create incentives for collaboration and reward knowledge sharing. Prioritize outcomes (business impact) over tool novelty, and create safe spaces for cross-role feedback so teams can continuously improve.
Case example (illustrative)
Imagine a retail company expanding its BI program to support personalized promotions. The team must deliver real-time stock levels, predictive demand models and marketer self-service dashboards. If data engineering, modeling and UX are siloed, the marketer receives dashboards with stale inventory and models that don’t incorporate seasonal signals. If the company instead defines clear dataset ownership, runs weekly cross-functional reviews, and keeps a living data catalog, the same project becomes manageable: engineers expose real-time feeds, modelers publish validated artifacts with clear assumptions, and UX designers deliver interfaces the marketers can use without ambiguity.
Key takeaways
- BI is broader now — expect to support streaming, prediction and self-service in addition to reporting.
- Specialization is necessary but must be counterbalanced by collaboration practices and shared documentation.
- Pick an agile approach that matches your risk tolerance and regulatory environment.
- Make documentation and data cataloging practical and integrated into your workflows.
- Cross-training is a small investment with outsized returns for speed and resilience.