Complex Computed Satellites
When people first learn about computed satellites in Data Vault, they often encounter very simple examples: concatenating first and last names into a full name, or applying a basic calculation within a satellite. While these examples are valid, they don’t capture the full breadth of what computed satellites can do. In reality, computed satellites are a powerful mechanism for integrating, transforming, and enriching data across your vault — enabling business-driven insights while maintaining the Data Vault principles of auditability and traceability.
This article will walk through the broader concept of computed satellites, discuss how they are designed, and provide practical implementation patterns for handling more complex use cases.
What is a Computed Satellite?
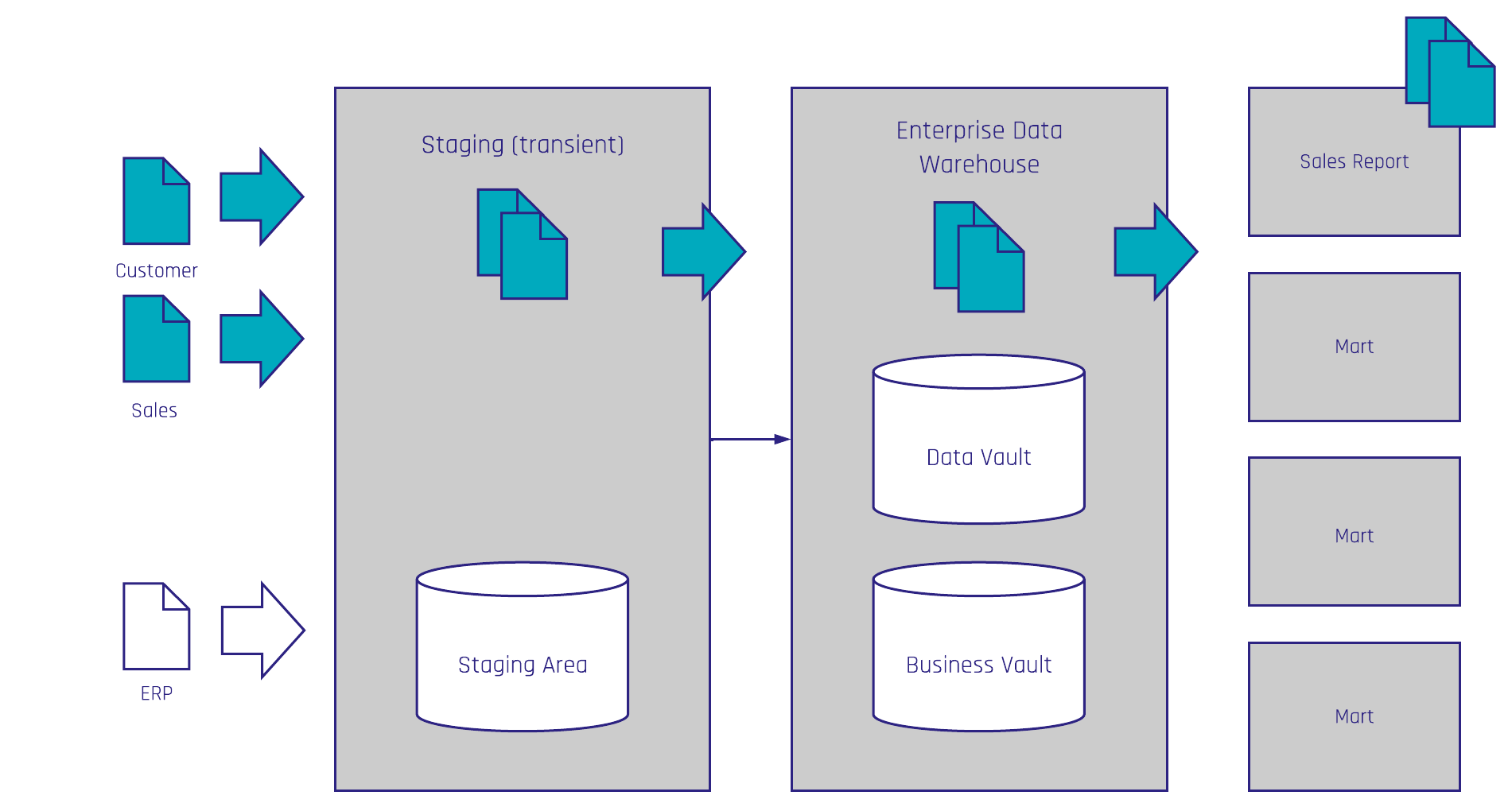
At its core, a satellite in Data Vault is a structure that describes a business object (a hub or link) by holding descriptive attributes over time. A computed satellite differs from a raw satellite because its data does not come directly from the source system but is derived through business logic.
Examples include:
- Concatenating
FirstName and LastName into FullName.
- Deriving an age from a birthdate.
- Producing calculated scores, risk categories, or classifications.
- Integrating attributes from multiple satellites across different hubs via links.
- Creating artificial relationships, such as product recommendations based on purchase history.
Importantly, a computed satellite isn’t just about the calculation itself — it’s about what the result describes and where it logically belongs in your model.
Step 1: Defining the Parent Entity
Before you build a computed satellite, you must answer a critical question: What does the result describe?
Every satellite attaches to either a hub (a business key) or a link (a relationship between keys). If your calculation produces attributes describing a customer, then the computed satellite belongs on the Customer Hub. If it describes a relationship between customers and products, it belongs on the respective link.
For example:
- A Full Name attribute describes a Customer Hub.
- A product recommendation score describes a Customer–Product Link.
- A risk category for an account describes an Account Hub.
This step ensures that your computed satellite stays aligned with the business meaning of your Data Vault model.
Step 2: Designing the Structure
Once you know the parent, the next step is to decide the structure of your results. Computed satellites can contain:
- Simple attributes (e.g., strings, numbers, dates).
- Multiple descriptive fields derived from logic.
- Semi-structured data, such as JSON or XML.
For example, you might calculate a JSON object capturing a customer’s segmentation profile, or an XML document describing a product configuration.
The important point: the satellite reflects the structure of your results, not the mechanics of how you implemented them.
Step 3: Implementing the Business Logic
After modeling comes implementation. Computed satellites can be populated in several ways:
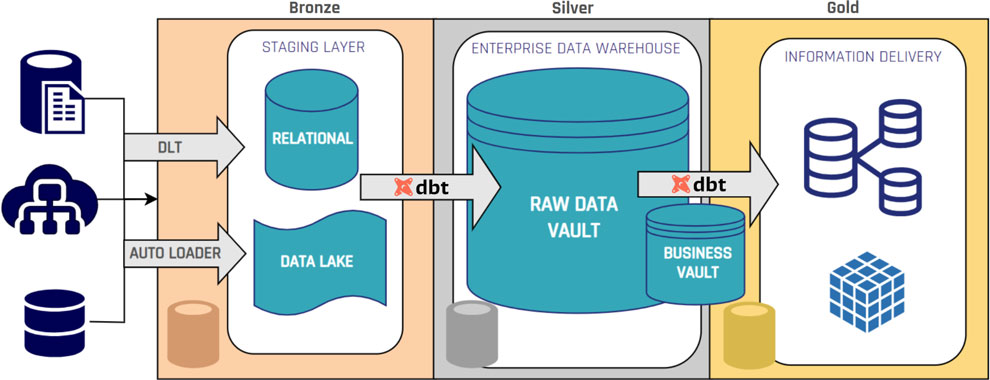
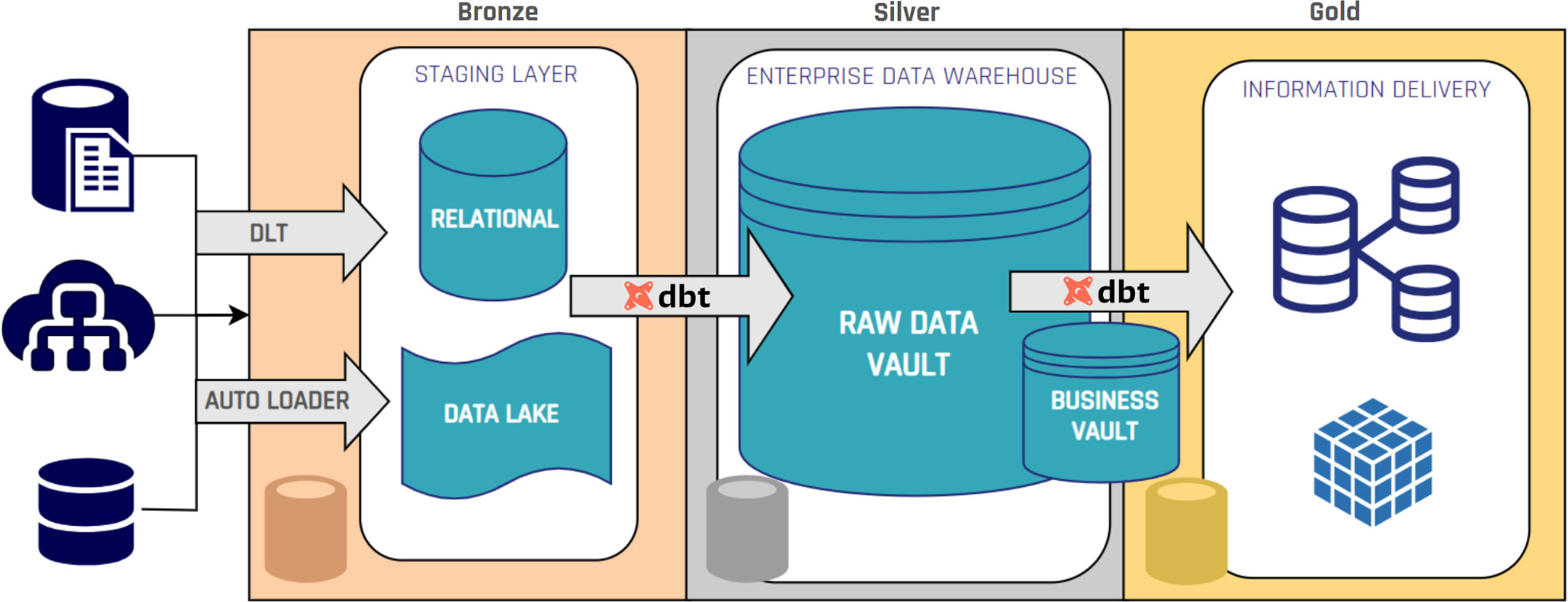
SQL Views
The most common approach is to implement a computed satellite as a SQL view. Here, the SQL query both expresses the logic (e.g., joins, transformations, calculations) and defines the result structure. If SQL is sufficient for your business rules, this is often the simplest and most maintainable approach.
External Scripts (Python, R, etc.)
For more advanced transformations, machine learning, or statistical processing, you may use external code. A Python script, for example, could pick up data from raw satellites, apply complex algorithms, and write results back into a computed satellite.
The golden rule: the implementation must remain under your control. Even if a data scientist creates an initial model using tools like Azure ML or RapidMiner, once it becomes part of your Business Vault, the deployment and maintenance are governed centrally. This ensures auditability and consistency.
Materialized Tables
Sometimes, business logic requires intermediate storage. In this case, you may materialize computed satellites as physical tables populated via INSERT statements or stored procedures. This is useful for performance optimization or managing dependency chains in cascading business rules.
Complex Use Cases for Computed Satellites
1. Filtering or Subsetting Business Keys
Imagine a Partner Hub with a single satellite. Business users may want to see only clients, employees, or vendors. Computed satellites can create filtered subsets that bring the model closer to business expectations. While not always the cleanest design, this is a practical option in some industries, such as insurance.
2. Artificial Links
A link doesn’t always need to come directly from a source system. You can create artificial links based on computed relationships. For example, by analyzing purchase history, you might generate product recommendations — effectively creating a Customer–Product Recommendation Link.
3. Cascading Business Rules
A powerful pattern is to break complex logic into smaller, reusable steps:
- Create a simple computed satellite that performs data cleansing or a basic calculation.
- Use that result in a second computed satellite to apply additional rules.
- Join results with other business vault entities to build richer attributes.
This cascading approach makes rules easier to maintain, document, and reuse — and avoids giant, unmanageable SQL queries filled with dozens of CTEs.
Best Practices
- Start with the business meaning: Always clarify what the result describes before modeling.
- Keep business logic in the Business Vault, not in downstream marts.
- Favor cascading rules over monolithic transformations — it improves maintainability and reusability.
- Control the code: All scripts, views, and procedures must be owned by the data warehouse team, not end-users.
- Support multiple technologies: SQL for straightforward logic, external scripts for advanced logic, and materialized tables where necessary.
Dependencies and Execution
When you cascade rules or materialize results, you introduce dependencies. One entity must load before another. To manage this, many teams implement dependency tables that track loading order. This enables recursive or automated job scheduling, ensuring consistency across the Business Vault.
Virtualized approaches (SQL views) are often easier, since query optimizers can resolve dependencies dynamically. Materialized approaches, however, provide better performance and control at scale.
Why Computed Satellites Matter
Computed satellites are more than “extra calculated fields.” They enable organizations to:
- Bridge the gap between raw data and business expectations.
- Implement business rules in a controlled, auditable environment.
- Support advanced analytics and machine learning workflows inside the Data Vault framework.
- Enable modular, reusable logic that scales across domains and use cases.
By treating computed satellites as first-class citizens in your Business Vault, you ensure that business logic is not scattered in marts, reports, or ad hoc scripts — but is instead centralized, governed, and reusable.
Conclusion
Computed satellites in Data Vault can be as simple as a concatenated name, or as complex as multi-step cascading business rules that derive artificial relationships. The key is to start by identifying what your result describes, attach the satellite to the correct parent, design the structure of your attributes, and then implement the logic in a controlled, maintainable way.
Whether implemented via SQL, Python scripts, or materialized processes, computed satellites should remain under the stewardship of your data warehouse team. By following best practices, you’ll unlock the full potential of the Business Vault — keeping it business-aligned, auditable, and ready for advanced analytics.