Summary
This video guide offers an in-depth tutorial on upserting data into a MySQL database from Salesforce using Mulesoft Anypoint Studio, featuring a decision mechanism to choose between insert or update operations.
The guide touches on the fundamentals of MySQL, introduces Mulesoft Anypoint Studio, explains the importance of selective data insertion, and is tailored for IT teams and Salesforce developers as well as Salesforce architects.
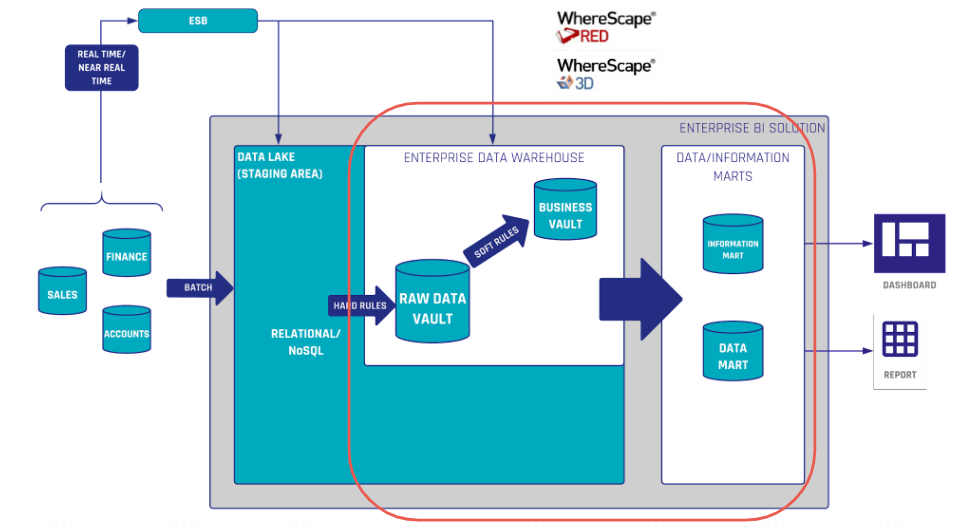
This process is vital for maintaining data integrity and synchronization between Salesforce and MySQL databases, ensuring accurate and current data across systems.
MySQL Quick Look
MySQL, as a leading open-source relational database management system, offers robust features for efficient data management, including support for complex queries, transactional integrity, and strong data protection mechanisms.
Its ability to handle large volumes of data with speed and reliability makes it an ideal choice for storing and managing the operational data of an organization.
Mulesoft Anypoint Studio
Mulesoft Anypoint Studio stands out as an integration development environment that enables developers to design, develop, and deploy complex integration solutions.
It supports a vast array of connectors, including those for Salesforce and MySQL, facilitating the easy exchange of data between disparate systems.
The platform’s visual interface and pre-built components allow for the rapid development of integration flows, including sophisticated logic like upsert operations, without extensive coding.
Why It Matters
The ability to upsert data—deciding between inserting new records or updating existing ones based on certain criteria—is crucial for maintaining data accuracy and consistency.
In environments where data is constantly changing, such as in CRM and operational databases, upsert operations ensure that data duplication is avoided and that the most current information is always available.
This capability is particularly important for businesses that rely on real-time data for decision-making, reporting, and customer relationship management.
Target Audience
The guide is specifically designed for IT professionals and Salesforce developers tasked with integrating and managing data across systems.
These individuals will find the tutorial valuable for understanding how to implement upsert operations within their data integration workflows.