Watch the Video
Mastering CDC Data in Data Vault 2.0
Change Data Capture (CDC) is a powerful mechanism for tracking changes in source systems. However, when the primary key in your source system differs from the business key used in your Data Vault hub, you may encounter challenges in loading data into multi-active satellites. This article explores various strategies for handling CDC data in such scenarios, offering practical solutions to ensure accurate and efficient data loading.
In this article:
Understanding the Challenge
In many source systems, the primary key is a technical identifier unknown to the business. Instead, the business key represents the meaningful identifier for a business object. In a typical scenario, the relationship between the primary key and the business key is one-to-one. However, in some cases, multiple records can be active for the same business key on the same date, resulting in multi-activity.
This situation arises when the primary key is unique at a given point in time, but the business key is not. For instance, you might have multiple customer IDs in your source system (primary keys) referring to the same customer (business key).
Solution 1: Verify Multi-Activity
Before diving into complex solutions, it’s crucial to verify whether the data is genuinely multi-active. In some cases, the appearance of multi-activity might be due to records being deleted and recreated with the same business key, resulting in different primary keys.
To check this, analyze the CDC data and other technical columns in the source system to determine the order of events. If a sequence of delete and create operations is detected, you may not be dealing with true multi-activity.
Solution 2: Create a Multi-Active Satellite with Delta Checking
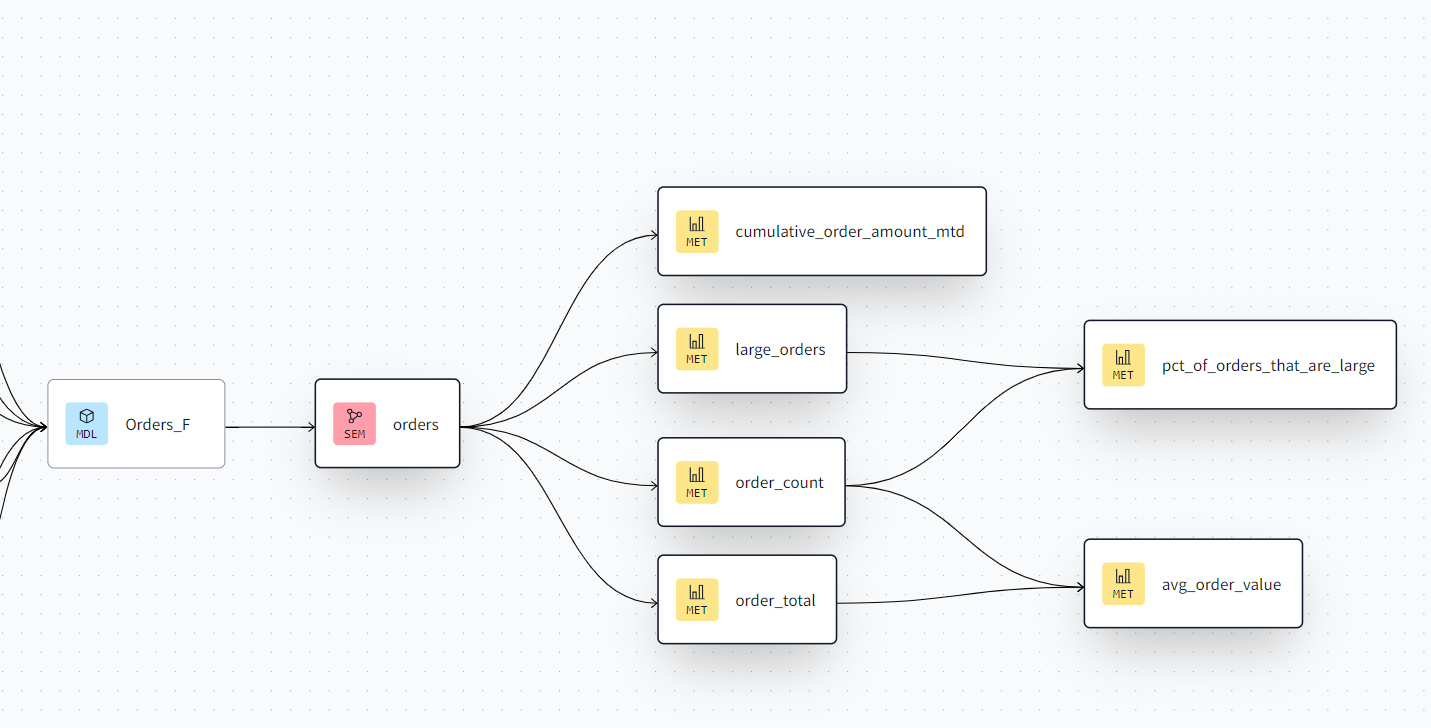
If the data is genuinely multi-active, the most straightforward approach is to create a multi-active satellite. Perform delta checks on the combination of the business key and the multi-active attribute (e.g., customer ID). This ensures that only changes within specific multi-active groups are loaded into the satellite.
However, this approach necessitates a specialized point-in-time (PIT) table, as the CDC data provides changes at the finest granularity (row level). You’ll need to consider both the load date timestamp and the multi-active attribute when querying the satellite to retrieve the most recent delta.
Solution 3: Remodel with Satellites on Links
Another option is to remodel your Data Vault structure by placing the satellite on the link. In this approach, the multi-active attribute becomes a dependent child key in the link, and a standard satellite is created on this link. This simplifies the handling of multi-activity within the link itself.
However, it’s important to note that the satellite in this case describes the relationship between the customer and other components, rather than directly describing the business object hub. Evaluate whether this modeling change aligns with your downstream querying requirements.
Solution 4: Use the Primary Key as a Technical Hub
As a last resort, you can use the primary key from the source system as a technical hub. This involves creating a hub for the primary key values (e.g., customer IDs) and linking it to the real customer hub using a same-as link. While not the preferred method, this can be a workaround in situations where other solutions are not feasible.
Additional Considerations
- CDC Data vs. Full Extracts: When dealing with full data extracts, even if only a part of the multi-active component changes, it’s best practice to insert the full block of data with the newest load date timestamp. This simplifies downstream processes and eliminates the need for a specialized PIT table.
- Non-History Links: If the CDC data represents transactional events and is analyzed as such, consider loading it into non-history links instead of satellites. This approach aligns with the transactional nature of the data and facilitates aggregations and trend analysis.
Conclusion
Handling CDC data in Data Vault 2.0 when dealing with multi-active satellites requires a careful assessment of your specific use case and data characteristics. The solutions presented in this article offer various approaches to tackle this challenge, each with its own advantages and trade-offs. By understanding these strategies and selecting the most appropriate one, you can ensure accurate and efficient data loading in your Data Vault environment.