Watch the Webinar

In this webinar, Michael Olschimke, the CEO of Scalefree, presents how to gain additional advantage from the enterprise data warehouse by making the solution available to power users and data scientists.
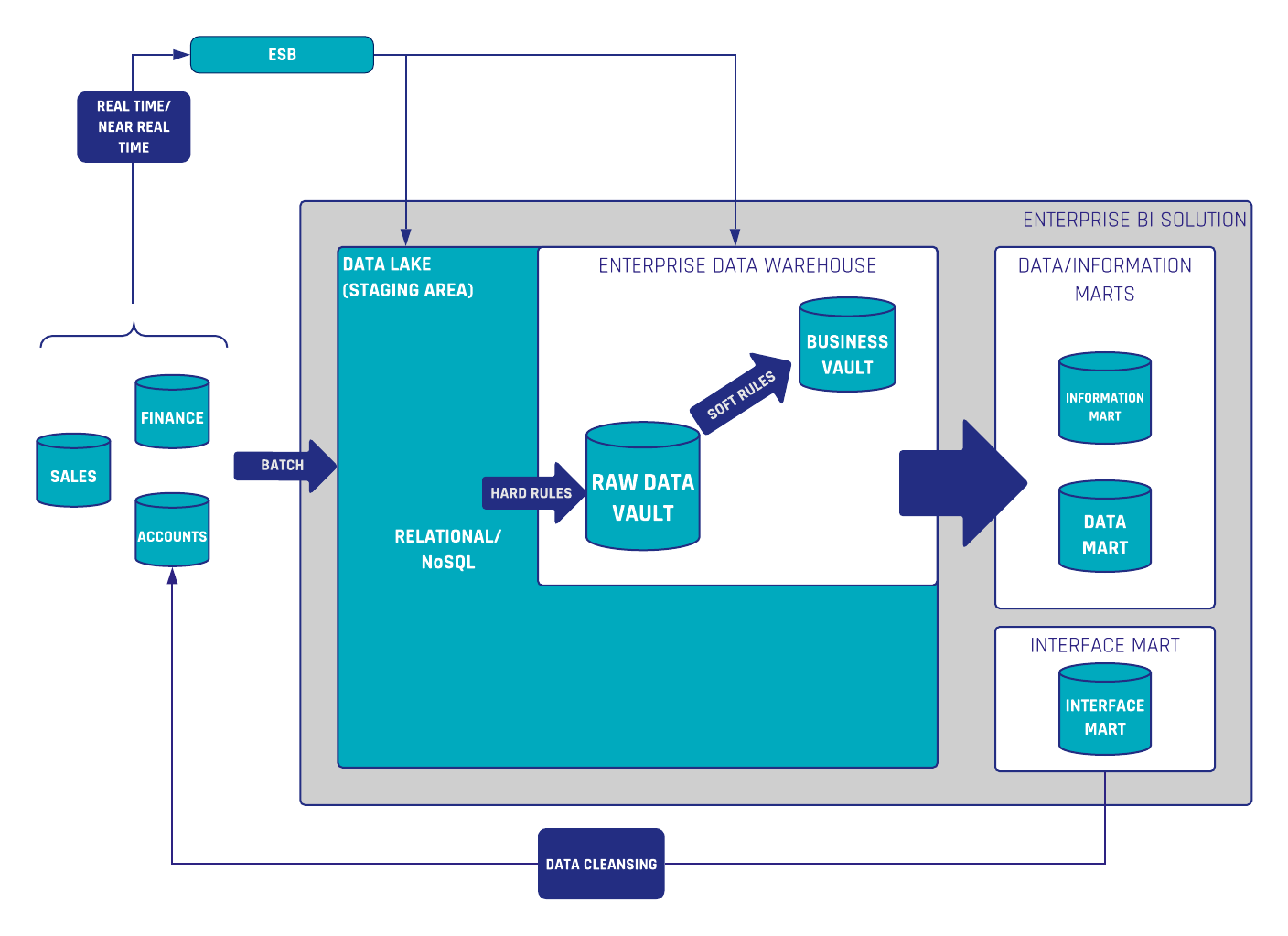
No one likes to wait! If you have to wait too long for data or information, you will find another way to get what you need. This will end up in different inconsistent data warehouse “solutions” in your company.
To avoid this, an agile approach with managed Self-Service BI is essential to keep a good relationship with Power Users (e.g. Data Scientists) and to build a governed enterprise BI solution for better decision-making. In this webinar, Michael Olschimke will talk about approaches, best practices, and experiences.
Webinar Agenda
1. About Data-Driven Organizations
2. Creating a Data-Driven Strategy
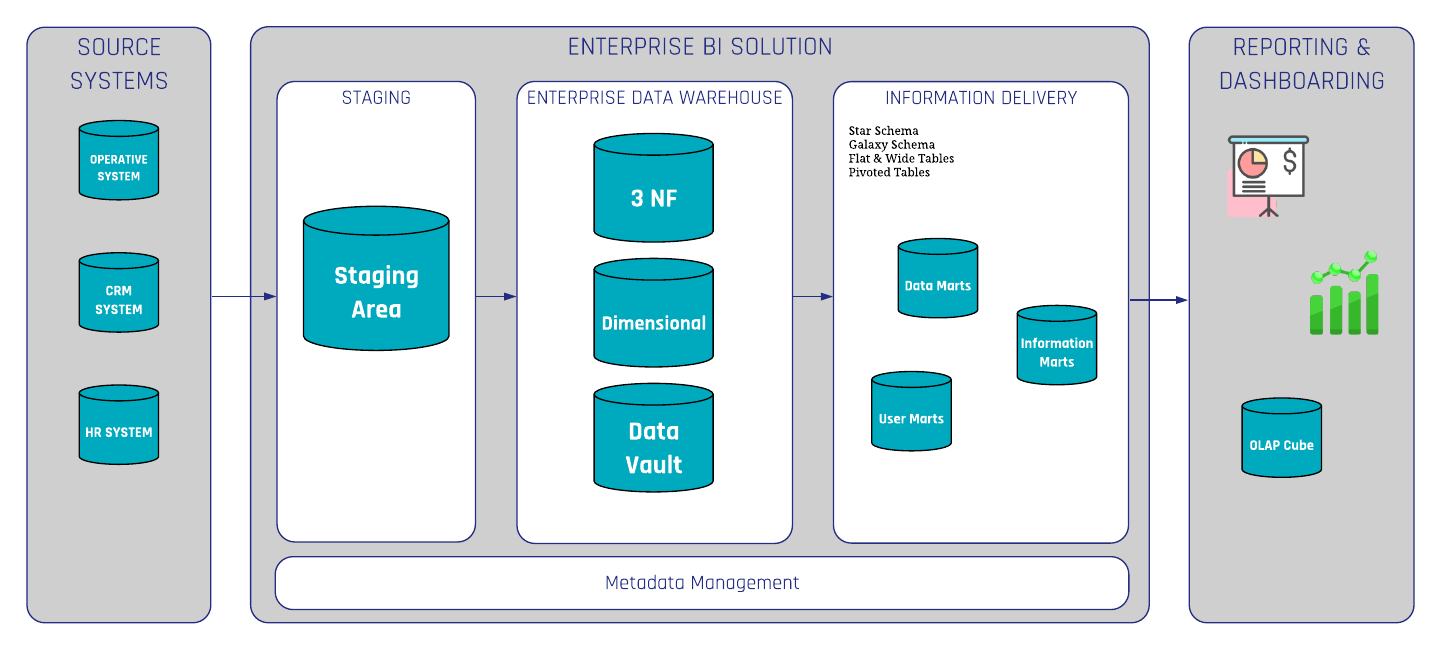
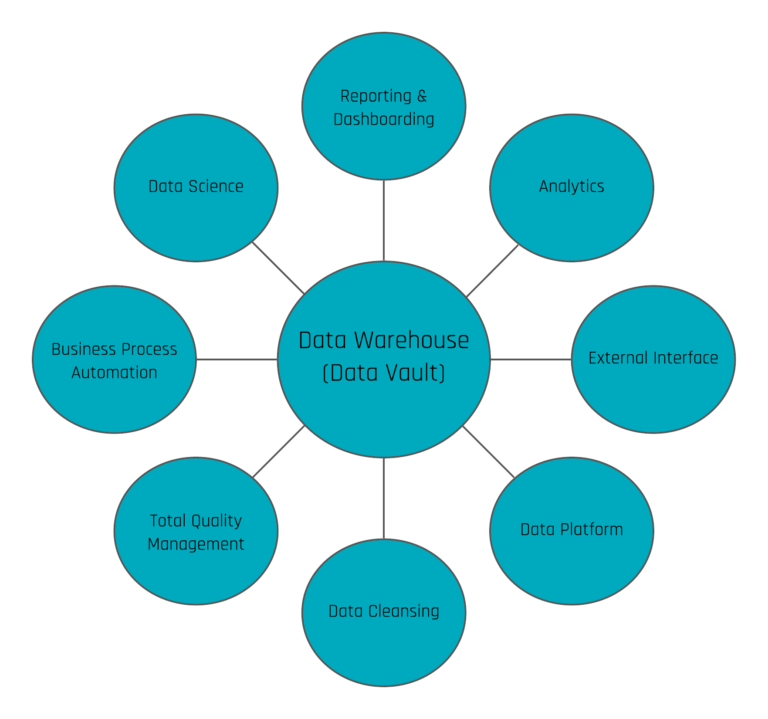
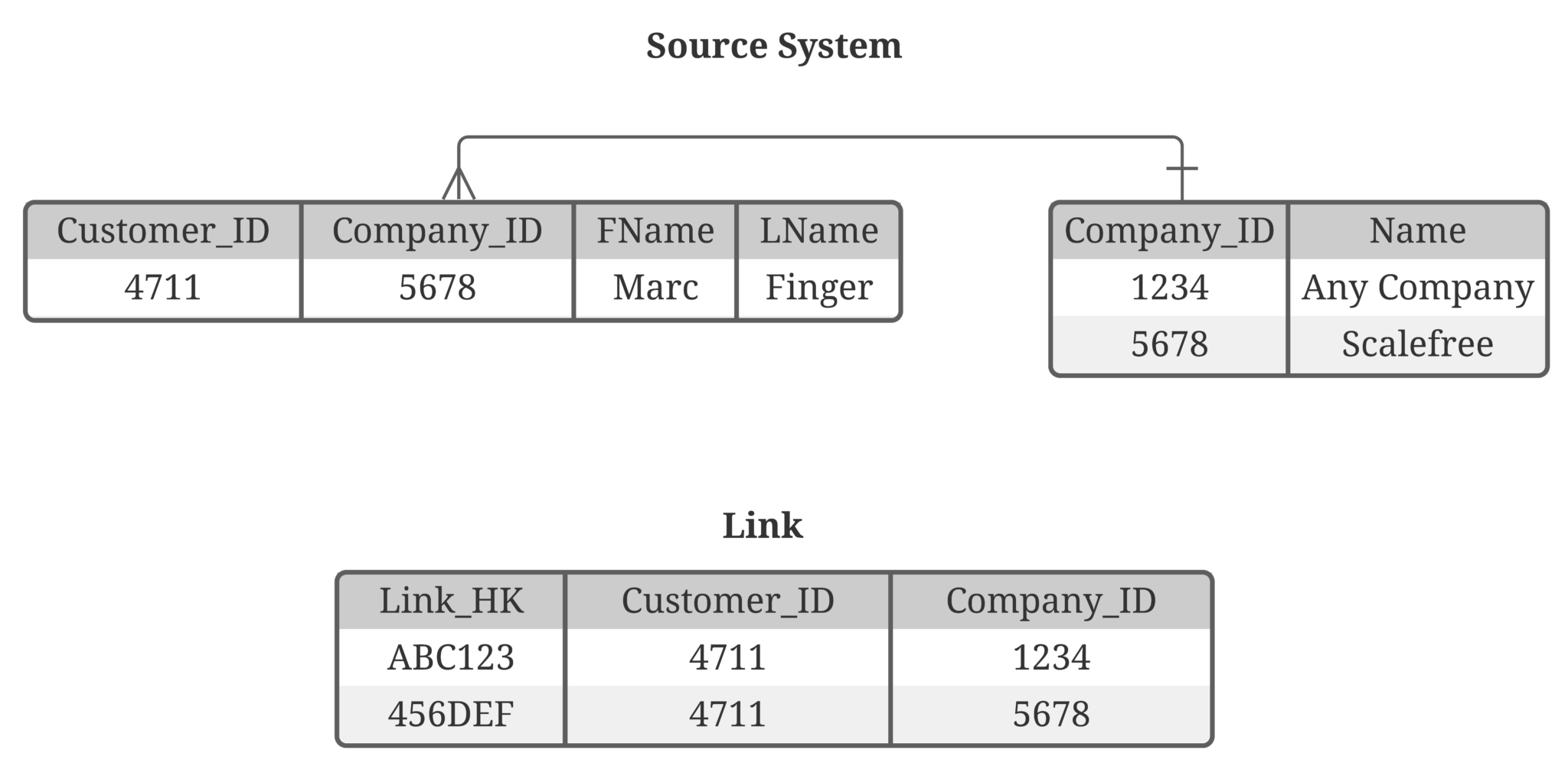
3. Making Data Available throughout the Enterprise