Watch the Video
In our ongoing Data Vault Friday series, our BI Consultant Julian Brunner delves into a question from the audience that addresses a common challenge.
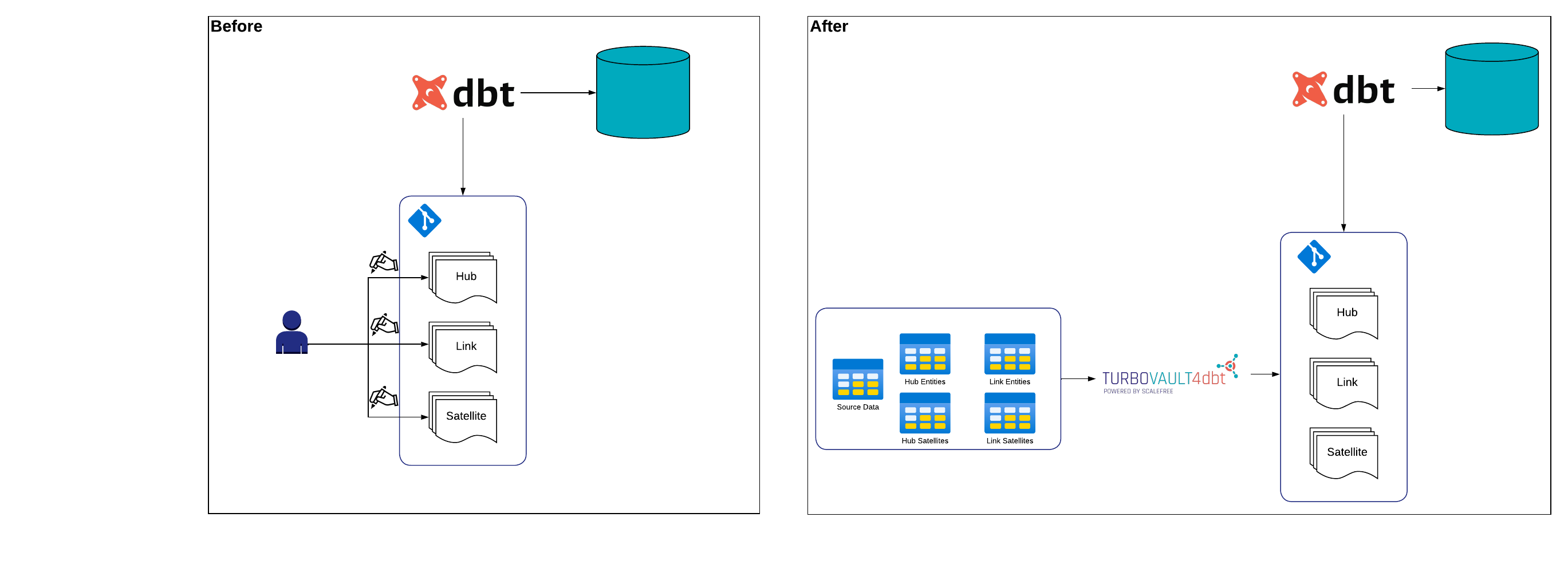
“One of our sources delivers all the historical data in one batch. So all the records have the same load date. How can I load the data into the EDW properly?”
In this insightful video, Julian shares practical solutions and strategies for loading historical data into an Enterprise Data Warehouse (EDW) when faced with the unique scenario of receiving all records with the same load date. The question prompts a discussion on best practices to ensure proper handling and integration of historical data within the Data Vault framework.
Julian provides valuable insights into the considerations and steps involved in effectively managing historical data loads, offering guidance on maintaining data integrity and accuracy within the EDW.