In our continuous Data Vault Friday series, our CEO Michael Olschimke engages with a set of pertinent questions posed by our audience.
“How to deal with dirty data managed in BV? What are the best practices for correct data management? How can business rules, versions, and fixes be managed on correction properly?”
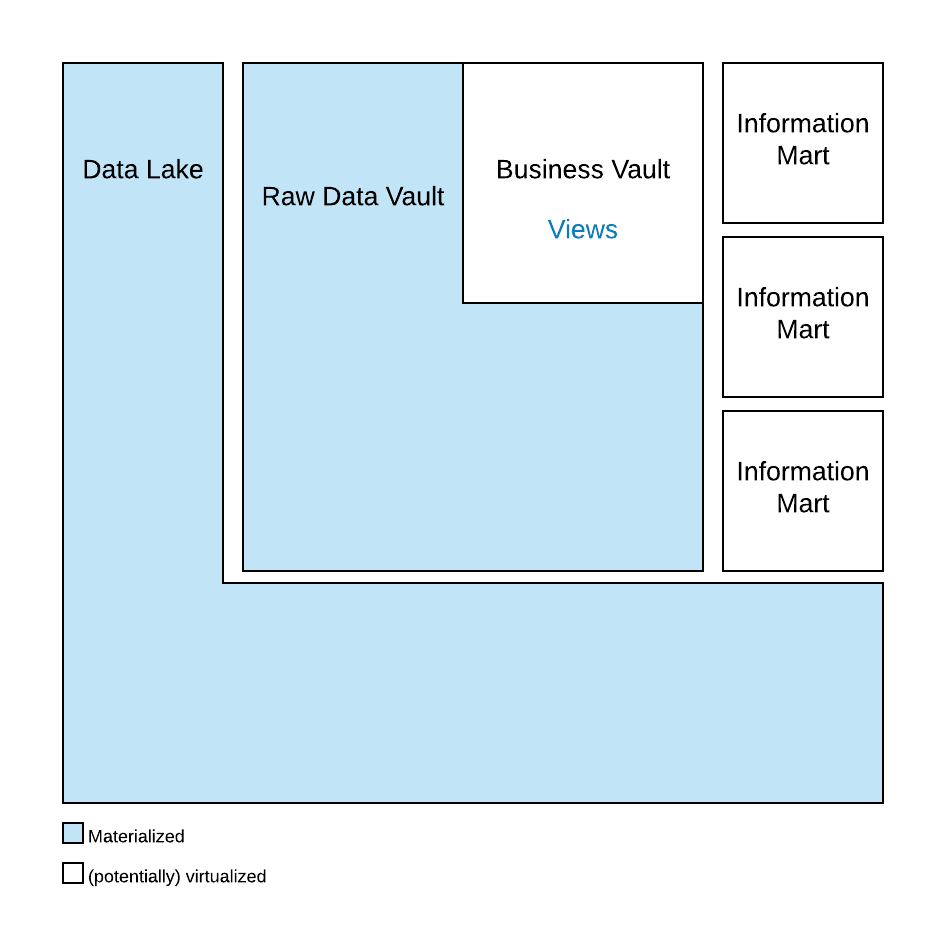
In this enlightening video, Michael addresses the challenges associated with handling dirty data within the Business Vault (BV) and explores best practices for effective data management. He dives into the complexities of managing business rules, versions, and corrections, offering insights into the proper approaches for ensuring data accuracy and consistency.
The video emphasizes a strict Extract, Load, Transform (ELT) approach, advocating for the application of data cleansing rules after loading the Raw Data Vault. Michael explains the rationale behind this methodology and highlights the advantages of maintaining a robust data flow.
For teams grappling with data quality issues and seeking optimal data management strategies, this video provides valuable guidance and practical considerations.