Data Vault on dbt Snapshots
In recent years, dbt has become one of the most popular tools in modern data stacks. At the same time, Data Vault continues to be a proven methodology for building scalable, auditable, and historically complete data warehouses.
It is therefore no surprise that questions arise at the intersection of both worlds. One question we recently received perfectly captures this:
“Can you build a Data Vault view downstream off of dbt snapshots?
I feel dbt snapshots are safer because they capture data ‘as is’, and a Data Vault might be designed wrong.”
This is a great question—and one that touches architecture, performance, data modeling, and risk management at the same time. In this article, we’ll unpack the topic step by step and give a clear, practical answer.
In this article:
- First Things First: What Are dbt Snapshots?
- dbt Snapshots vs. Data Vault Satellites
- Why Insert-Only Matters in the Cloud
- Where dbt Snapshots Shine
- Back to the Core Question
- The Real Challenge: Performance and Cost
- Does a “Wrong” Data Vault Design Mean Data Loss?
- A Pragmatic Recommendation
- Final Thoughts
- Watch the Video
First Things First: What Are dbt Snapshots?
Before we compare dbt snapshots with Data Vault concepts, let’s align on what dbt snapshots actually are.
According to dbt’s own documentation, snapshots are used to implement Type 2 Slowly Changing Dimensions (SCD Type 2) on mutable source tables.
If you’re familiar with dimensional modeling, this should sound very familiar. SCD Type 2 means:
- Whenever a record changes, a new row is inserted.
- The old version of the record is kept for historical analysis.
- Validity timestamps define from when to when a record version was valid.
In a typical example, a source table might only store the current state of an order:
- January 1st: Order status = pending
- January 2nd: Order status = shipped
The source system overwrites the status, so you only ever see the latest value. But in analytics and data warehousing, we usually want to know how the data looked at a specific point in time.
That’s where dbt snapshots come in. They store multiple versions of the same business key and enrich the data with technical columns such as:
dbt_valid_fromdbt_valid_to
Whenever dbt detects a change, it:
- Inserts a new row for the new version.
- Updates the
dbt_valid_toof the previous version.
From a functional perspective, this is classic SCD Type 2 behavior.
dbt Snapshots vs. Data Vault Satellites
Now let’s compare dbt snapshots with Data Vault modeling. This is where things get interesting.
In Data Vault, Satellites are responsible for storing descriptive attributes and tracking changes over time. In other words:
- Satellites are also SCD Type 2 structures.
- They store full history.
- They insert a new row for every detected change.
So at first glance, dbt snapshots and Data Vault satellites look almost identical. And conceptually, they are very close.
However, there is one important difference.
Insert-Only vs. Update-Based Modeling
Modern Data Vault implementations follow a strict insert-only approach. That means:
- No updates to existing records.
- No physical
valid_tocolumn updates. - History is reconstructed using window functions or Point-in-Time (PIT) tables.
dbt snapshots, on the other hand, do update the previous record to set the dbt_valid_to timestamp.
From a pure modeling perspective, both approaches are valid. But from a platform and performance perspective, insert-only has some strong advantages—
especially in cloud data warehouses like Snowflake, BigQuery, or Redshift.
Why Insert-Only Matters in the Cloud
Cloud-native data warehouses are optimized for append-heavy workloads.
For example:
- Snowflake uses micro-partitions that are immutable.
- Updates often result in copy-on-write operations.
- Insert-only workloads scale better and are cheaper.
This is one of the reasons why Data Vault adopted insert-only patterns years ago. It’s not just about modeling philosophy—it’s about performance and scalability.
That doesn’t mean dbt snapshots are “wrong”. It just means they were designed with a slightly different use case in mind.
Where dbt Snapshots Shine
From a practical standpoint, dbt snapshots are extremely useful in specific scenarios.
One very common use case is a persistent staging area.
Imagine you receive:
- Full data extracts every day from a source system.
- No CDC (Change Data Capture).
- Large tables where storing daily full loads would be wasteful.
In this case, dbt snapshots allow you to:
- Store only the changes between loads.
- Keep historical versions.
- Reduce storage and processing overhead.
From this perspective, dbt snapshots act like a slim persistent staging layer. They capture the source data “as is” and preserve history.
If you already receive proper CDC data from upstream systems, then dbt snapshots are often unnecessary. The change tracking has already been done for you.
Back to the Core Question
So let’s return to the original question:
Can you build a Data Vault view downstream of dbt snapshots?
Technically and conceptually, the answer is:
Yes, you can.
If your dbt snapshots contain all source changes, you have everything you need to:
- Identify business keys.
- Track attribute changes.
- Build hubs, links, and satellites.
In theory, you could build a fully virtualized Data Vault layer on top of snapshots:
- Virtual hubs
- Virtual links
- Virtual satellites
From a data completeness perspective, nothing is missing.
The Real Challenge: Performance and Cost
Unfortunately, theory and reality often diverge.
While a fully virtualized Data Vault sounds elegant, it usually doesn’t work well in practice—at least not today.
Why?
- Large historical datasets require heavy joins and window functions.
- Virtualization pushes computation to query time.
- Cloud compute costs increase rapidly.
In most real-world environments, fully virtualizing the Data Vault on top of snapshots leads to:
- Slow queries
- High compute bills
- Poor user experience
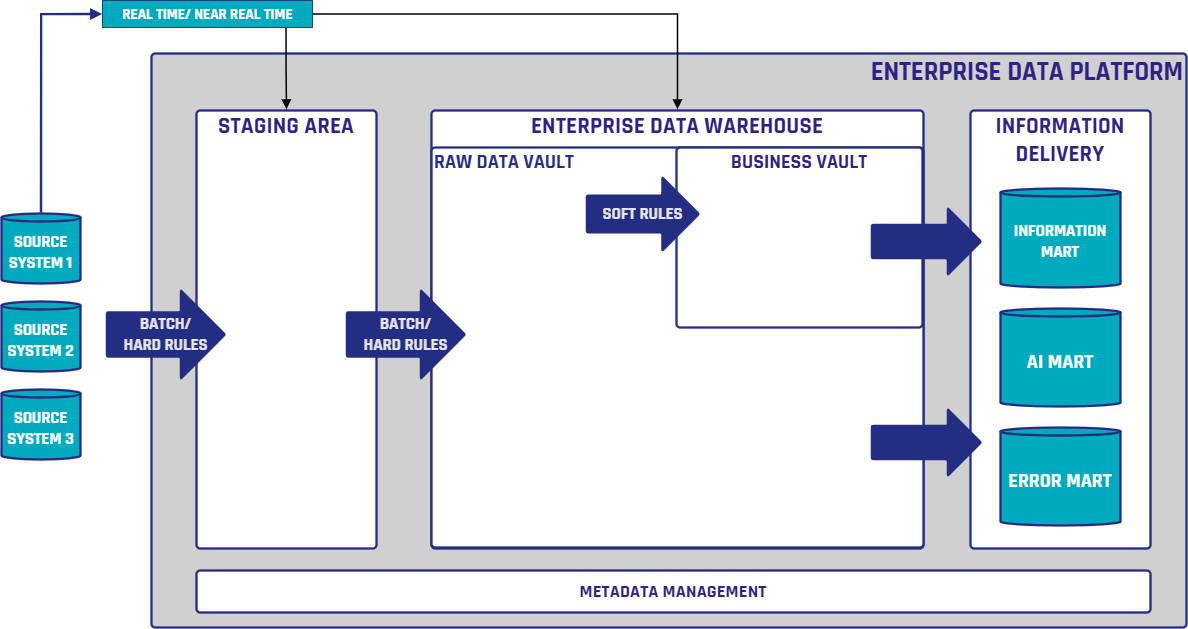
That’s why most architectures still materialize the Data Vault at some point.
Does a “Wrong” Data Vault Design Mean Data Loss?
Another concern in the question is the fear of designing the Data Vault “wrong”.
This fear is understandable—but largely unfounded.
One of the core promises of Data Vault is:
You do not lose data due to modeling decisions.
Even if:
- You split satellites too much.
- You group attributes differently than you would today.
- You later realize a better modeling pattern.
You can always:
- Refactor satellites.
- Split or merge them.
- Reload data from existing Data Vault tables.
This is possible because Data Vault stores raw, historized data—not business logic.
So while a persistent staging area can be helpful, it is not a safety net you absolutely must have. A properly loaded Data Vault already is that safety net.
A Pragmatic Recommendation
So what does a pragmatic architecture look like today?
- Use dbt snapshots if you need a persistent staging layer and don’t have CDC.
- Materialize the Raw Data Vault for performance and scalability.
- Virtualize downstream layers (Business Vault, Information Marts) where possible.
This approach balances:
- Data safety
- Performance
- Cost efficiency
As data volumes grow and histories span years or decades, full virtualization simply becomes inefficient. Materialization at the Raw Vault level is still the sweet spot in most projects.
Final Thoughts
dbt snapshots are a powerful feature and fit nicely into modern data stacks. They can absolutely support Data Vault architectures—especially as a persistent staging layer.
However, they don’t eliminate the need for a materialized Data Vault. Nor do they replace the robustness and flexibility that Data Vault modeling provides.
Used together, dbt and Data Vault can form a strong, future-proof foundation for enterprise analytics—when each tool is applied where it makes the most sense.