Snapshot Based Bridge Table on Link and Effectivity Satellite
Welcome to another edition of Data Vault Friday! Today, we’re diving into the concept of a snapshot-based bridge table, particularly focusing on its application in scenarios with links and effectivity satellites. This approach helps us handle complex relationships between business objects over time, managing changes in relationships, and retaining a complete historical view. In this article, we will explore solutions to three main questions:
- How to handle a missing relationship on day 2 compared to day 1
- How to manage changed relationships from day 1 to day 2 for the same key
- How to include a business object (A3) on day 2 when it lacks a relationship to any object in B
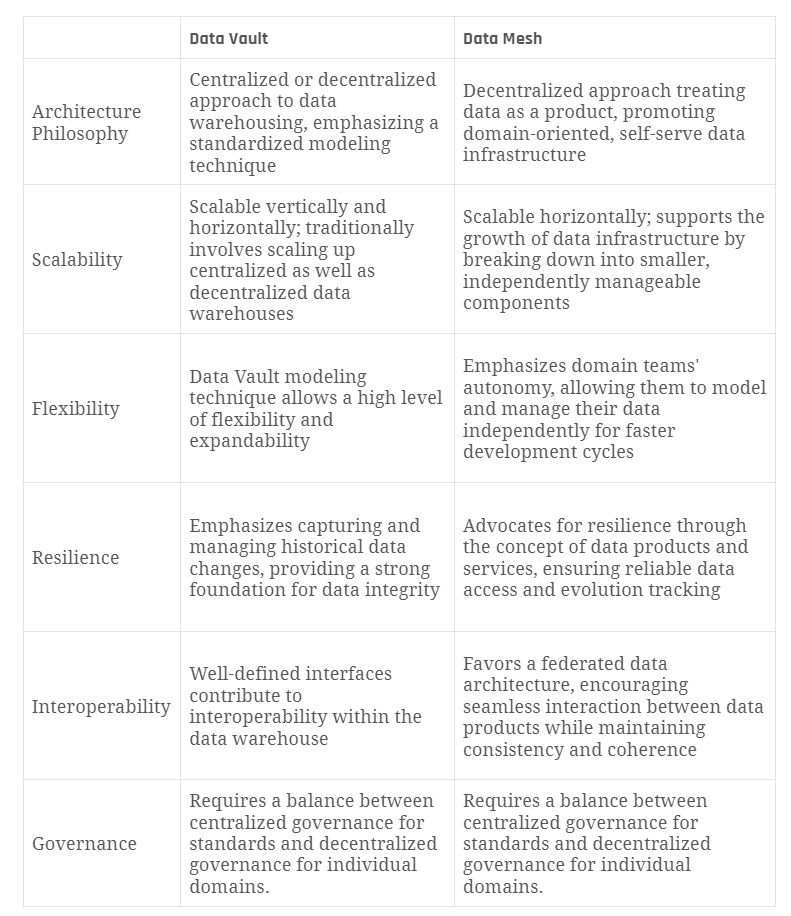
Understanding the Data Vault Modeling Example
In our example, we have two sources, each representing a different business object (A and B). Business object A is represented as a static dataset, while business object B shows dynamic relationships to A over three days. Each day brings changes in the relationships, with some entries disappearing or shifting. Our task is to capture these changes effectively in a snapshot bridge table.
Examining the Relationship Changes
Let’s walk through the changes observed over three days:
- Day 1: B1 is related to A1, B2 to A2, and B3 to A3.
- Day 2: The relationships change. B1 is now related to A2, B2 to A1, and B3 disappears.
- Day 3: No further changes occur compared to Day 2.
Our objective is to document these relationships using an Effectivity Satellite and a Bridge Table, enabling us to query the state of relationships as they existed on each day.
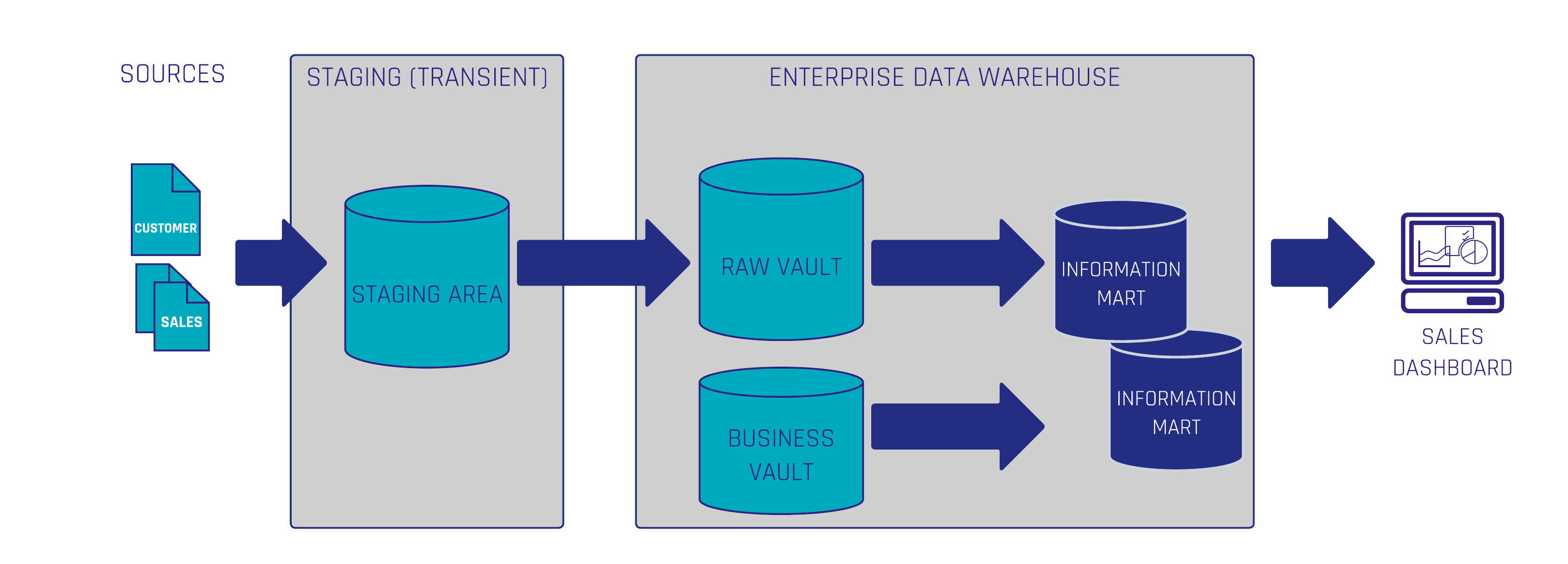
Creating the Link and Effectivity Satellite
The first step in capturing these relationships is to create a Link table that holds a distinct list of relationships between business objects. Links should not have additional metadata, such as validity dates, as this can complicate data retrieval and reduce performance. In our example, the Link table captures each unique combination of A and B keys but does not record their start or end dates.
Next, we create an Effectivity Satellite. This table extends the Link by recording each relationship’s start and end timestamps, as well as an “is_active” flag to indicate the current status of each relationship. Using this table, we can track when a relationship starts, changes, or ends. Let’s examine how this works:
- Day 1 entries: All relationships (B1-A1, B2-A2, B3-A3) are marked as active.
- Day 2 entries: New relationships (B1-A2 and B2-A1) are added and marked active, while previous relationships (B1-A1 and B2-A2) are marked inactive. B3-A3 is removed entirely.
Building the Snapshot-Based Bridge Table
With the Effectivity Satellite in place, we can now create a Bridge Table that snapshots the active relationships for each day. This table provides a point-in-time view of the relationships as they existed on a particular day. Let’s look at how the Bridge Table is created:
Day 1 Snapshot
The Day 1 snapshot reflects the initial relationships, pulling all active records from the Effectivity Satellite. At this stage, B1-A1, B2-A2, and B3-A3 are all active.
Day 2 Snapshot
In the Day 2 snapshot, only the relationships B1-A2 and B2-A1 remain active, while B3-A3 is removed. By applying a filter to include only active entries, the snapshot accurately represents the relationships on Day 2.
Day 3 Snapshot
Day 3’s snapshot is identical to Day 2, as no additional changes were made. The active relationships B1-A2 and B2-A1 remain unchanged.
This process ensures we have a clear audit trail of relationship changes and deletions. Each day’s snapshot represents the state of relationships at that point in time, without introducing redundant data.
Handling Missing Data and Reinstating Relationships
One critical feature of the Effectivity Satellite is the ability to manage reinstated relationships. For instance, if B1-A1’s relationship is reestablished on Day 4, we add new rows in the Effectivity Satellite, marking the previous active combination (B1-A2) as inactive and reactivating B1-A1. This dynamic structure makes it easy to adjust for relationships that appear, disappear, and reappear over time.
Incorporating A3 in the Bridge Table on Day 2
A common challenge is how to incorporate business objects like A3 on Day 2, despite having no relationship in B on that day. In Data Vault, this is often addressed in downstream queries or report joins rather than in the Bridge Table itself.
By starting with object A and performing a left join to the Bridge Table, you will include all records from A (even if they don’t appear in B). This ensures that unlinked objects are included in the results, with their B relationships shown as null, or as a placeholder if desired.
Preventing Cartesian Products and Other Best Practices
When using a Bridge Table, it’s essential to avoid unexpected Cartesian products, which can inflate data during aggregation. Always check the cardinality of relationships between objects (e.g., one-to-one or many-to-many) to ensure joins occur only on necessary keys. The driving key, which anchors the relationships in the Link Table, should be the primary focus, especially in cases of many-to-many relationships.
This method ensures accuracy and performance when aggregating data and avoids inflated results in reporting.
Conclusion
Snapshot-based bridge tables are powerful tools in Data Vault modeling for handling changing relationships and tracking historical snapshots. By carefully structuring Links, Effectivity Satellites, and Bridge Tables, we create a robust, auditable trail of data changes over time. As we’ve discussed, this approach allows us to accommodate missing data, reinstate relationships, and prevent data inflation, ensuring reliable, performant data models.
If you’d like further assistance with templates for bridge tables or Effectivity Satellites, feel free to reach out to me. I hope this discussion has provided clarity on using bridge tables in Data Vault. Join us again for more Data Vault insights, and feel free to submit your questions!