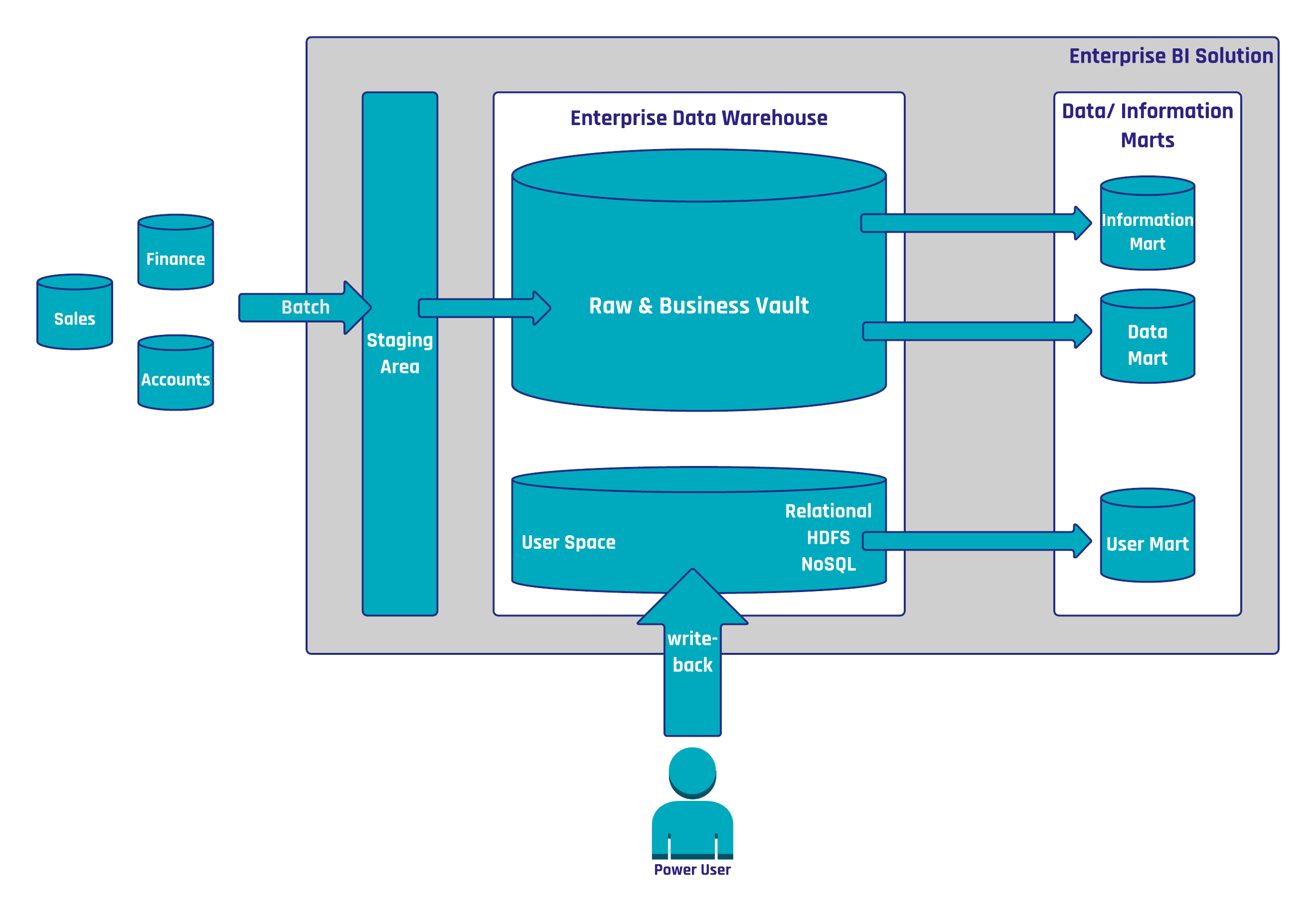
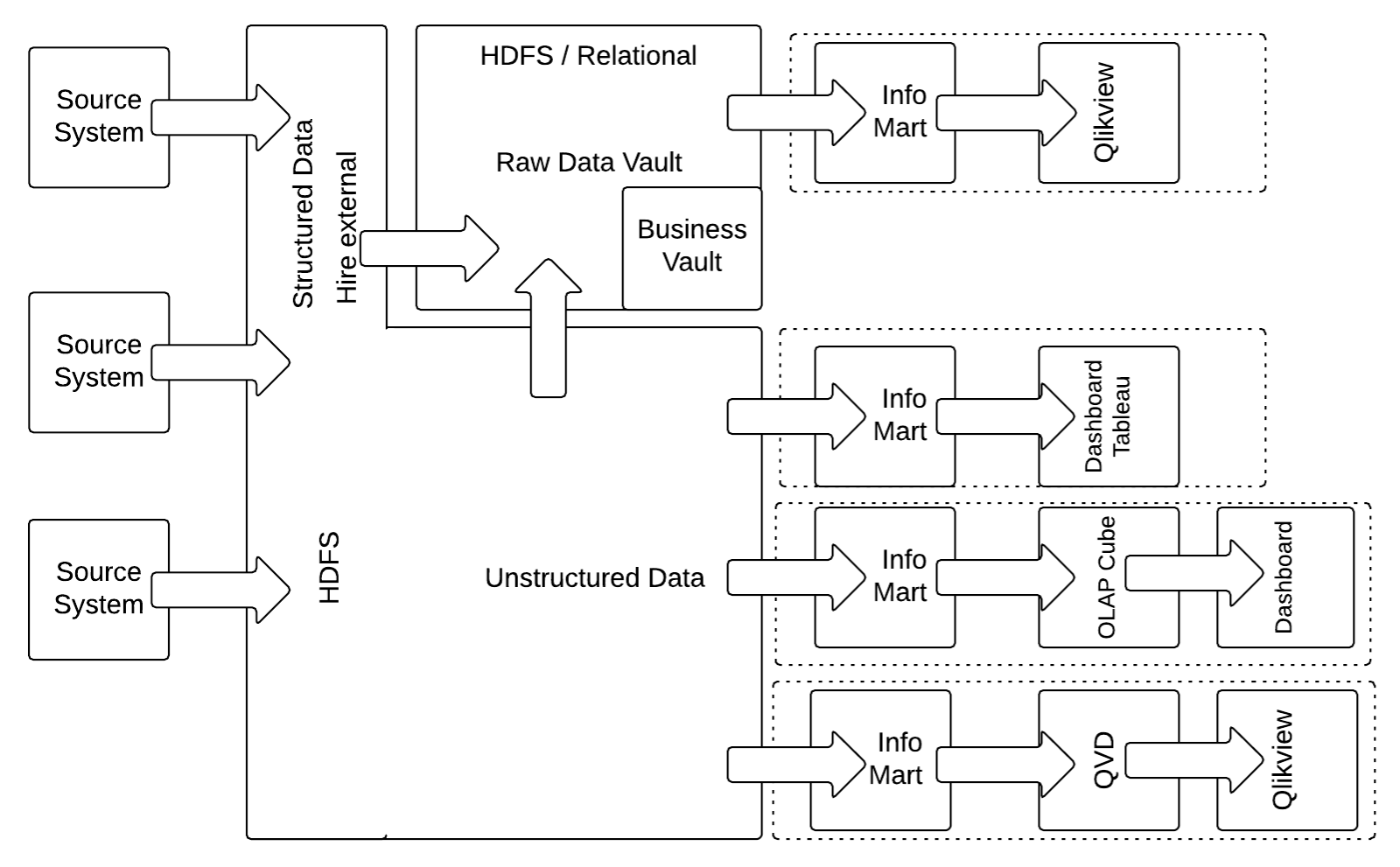
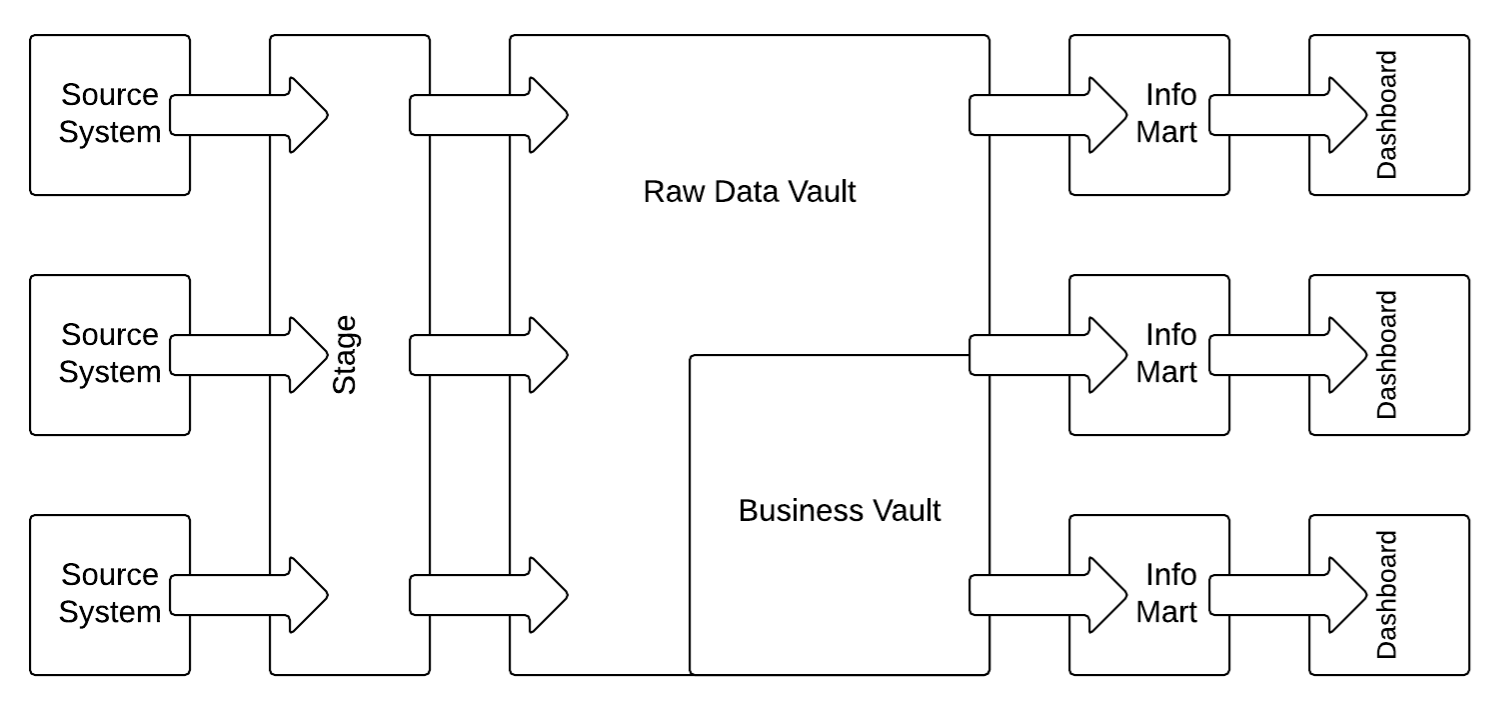
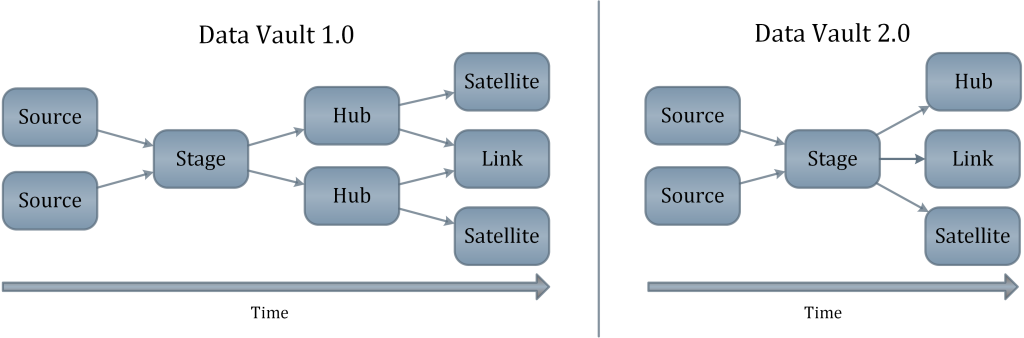
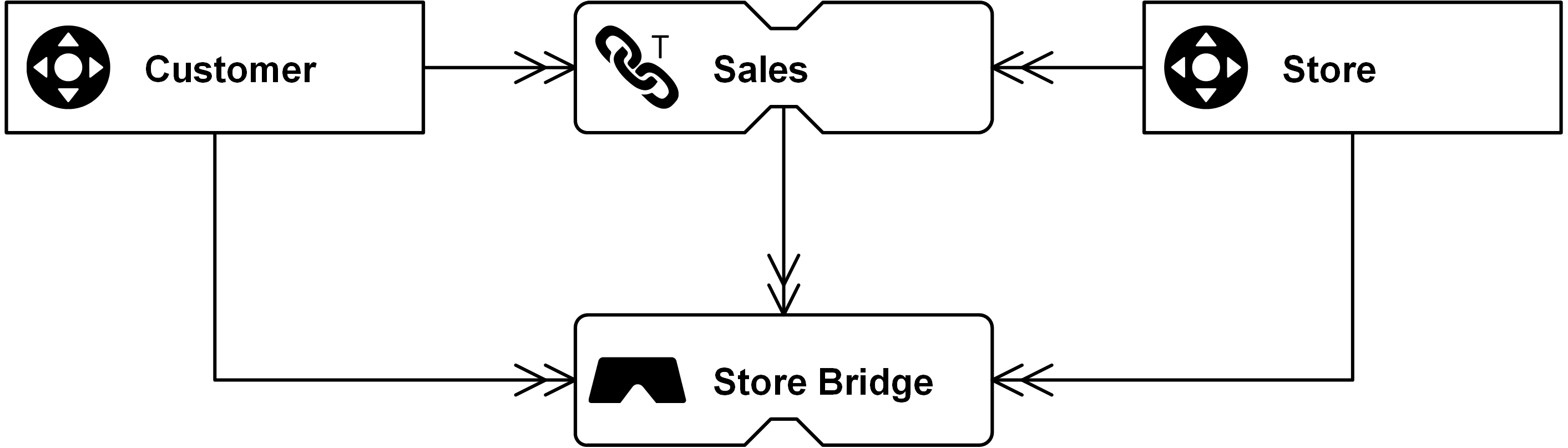
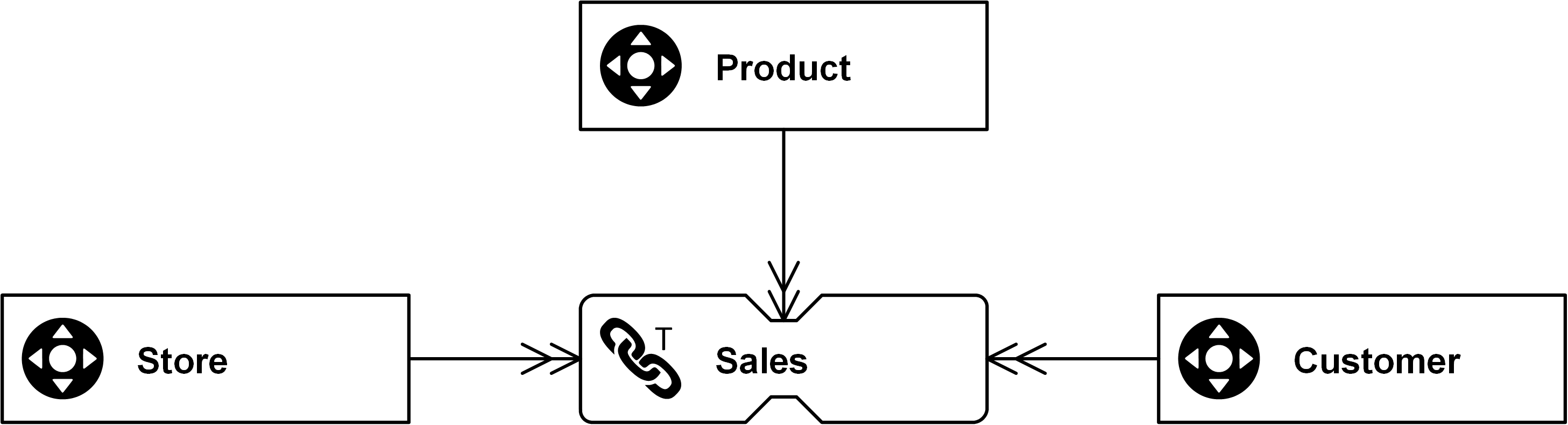
In this example, Sales can be modeled with non-historized links that capture sales transactions of a customer, related to a store. The goal of the non-historized link is to ensure high performance on the way into the data warehouse and on the way out. Don’t forget, that the ultimate goal of data warehousing is to build a data warehouse not just model it. And building a data warehouse involves much more than just the model: it requires people, processes, and technology.
Key Characteristics of Non-Historized Links
So, how do non-historized links meet these goals? Think about your business analysts. What are their goals? In the end, to be honest, they don’t care about a Data Vault model. Instead, they would like to see dimensional models, such as star schema’s and snowflake models or flat-and-wide models for data mining. Or, once in a while, they want to see the ugly-looking tables from the mainframe, sometimes linked, sometimes not, and not a lot of people fully understand the relationships anymore…but for backward compatibility, that’s just great.
Having defined the target, the next question comes into mind: what is the target granularity? For example, in a dimensional model, the target granularity of fact tables often reflects the transactions to be analyzed (think about call records in the telecommunications industry or banking transactions).
Interestingly, this desired target granularity can often be found directly in the source systems. Because a telecommunications provider has an operational system in place that records each phone call. Or a banking application that records every account transaction. These records are typically loaded to the data warehouse without aggregation (at least in Data Vault where we are interested in the finest granularity for auditing and delivery purposes).
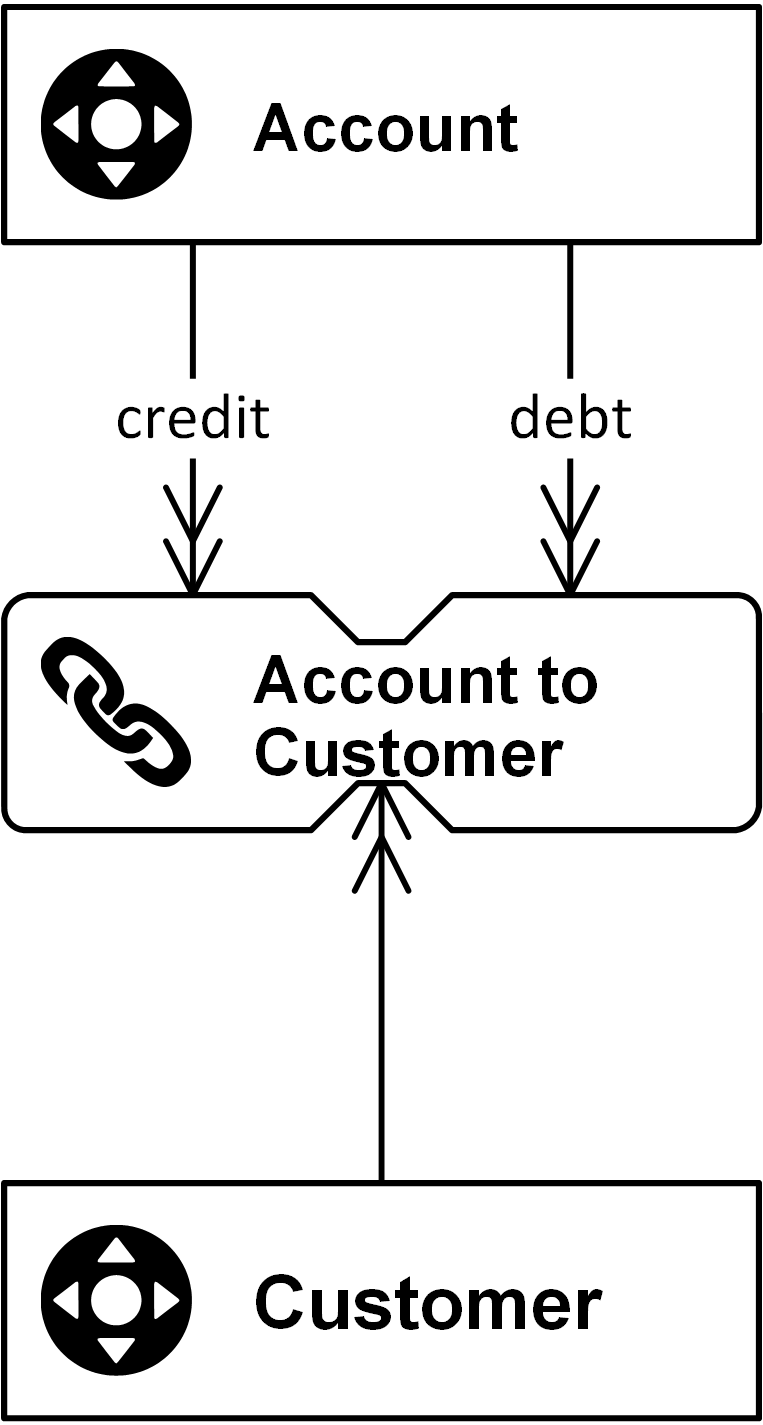
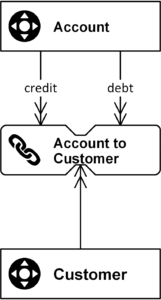
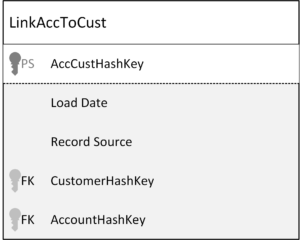
And here comes the problem with the standard Data Vault entity types. While they are very simple and patternized, they have one problem. It’s the fact that the standard link “stores a distinct list of relationships”, as stated above. That means the link is only interested in relationships from the source that are unknown to the target link. If a customer walks into a store multiple times and purchases the same product, the relationship between the customer (number), store (number), and product (number) is already known and no additional link entry is added.
As a result, the granularity of the incoming data is changed when loading the target link. If the transaction’s underlying relationship is already known, the transaction would be omitted (and instead captured by a satellite).
The next problem is that the link granularity now differs from the target granularity because the business analyst wanted one record per transaction and not per distinct business key relationship. Another grain shift is required that typically involves joining the satellite of the link to the link itself to recover the original grain.
As we explained in our book “Building a Scalable Data Warehouse with Data Vault 2.0” a grain shift is relatively costly in terms of performance. This is because the operation requires costly GROUP BY statements or LEFT and RIGHT JOINS.
And for what? The end result of both operations often results in the original granularity from the source system. Two expensive grain shifts for nothing sounds like a bad deal.